深入理解 Nsight Systems 与 Nsight Compute

本页主题:DEEP DIVE INTO NSIGHT SYSTEMS & NSIGHT COMPUTE。
工具:Nsight Systems (nsys)、Nsight Compute (ncu)。
目标:首先对NVIDIA的Profiler工具作为概述,接下来重点介绍新一代的NSIGHT System和NSIGHT Compute
01. 全课结构(Overview)
- Overview of Profilers
- Nsight Systems
- Nsight Compute
- Case Studies
- Summary

这一页是全课结构:先回顾 profiling 工具谱系,再分别讲 Nsight Systems(系统级) 和 Nsight Compute(kernel 级),最后用 case study 串起来并总结。
学习建议:先把“定位流程”记牢(先系统后 kernel),再去记具体 UI/指标。
- 每一节目标不同:
- Systems:找“空洞/等待/同步/数据搬运”
- Compute:找“哪个硬件单元限制/为什么 stall”
Systems vs Compute:分工与定位闭环
Nsight Systems:系统级(宏观定位)
- 侧重 系统级时间线:CPU 线程、CUDA API、kernel/memcpy、同步等待。
- 用于宏观定位瓶颈:
- 不必要同步
- 数据传输
- CPU 发射慢导致 GPU 空闲
- 等待/依赖造成的 idle gaps
Nsight Compute:kernel 级(微观定位)
面向 kernel 级分析:
- SOL(Speed Of Light)
- memory/compute
- scheduler
- stall reasons
用于微观定位与优化:
- 判断 compute-bound / memory-bound / latency-bound
- 解释“为什么 stall”“卡在何处”
02. 工具演进与迁移建议

旧工具 → 新工具
- 旧工具:NVVP(Visual Profiler)、nvprof(命令行)
- 局限:定位不清、文件大时很慢
- 未来 CUDA 版本中 逐步弃用
- 新一代推荐:Nsight Systems + Nsight Compute
落地动作
- 新项目:直接用 nsys / ncu
- 老项目:脚本若还在用 nvprof,尽快替换成 ncu-cli(nv-nsight-cu-cli)
Nsight Compute / Graphics 做什么(按应用类型)
- Compute 程序(CUDA 计算为主):
先用 Nsight Systems 排查系统级 → 再用 Nsight Compute 优化 kernel。 - Graphics 程序(图形渲染为主):
下钻用 Nsight Graphics 分析 frame/render。
本课程范围:只覆盖 Compute 程序,因此只讲 Nsight Systems + Nsight Compute。
标准迭代流程(闭环)
- 先用 Nsight Systems 做系统级分析 → 找到瓶颈点(同步/传输/调度等)
- 再用 Nsight Compute 优化热点 kernel(或 Graphics 优化渲染)
- 优化后回到 Nsight Systems 复测整体效果
- 不断重复,直到达到目标性能
03. Nsight 家族“入口图”的核心方法论
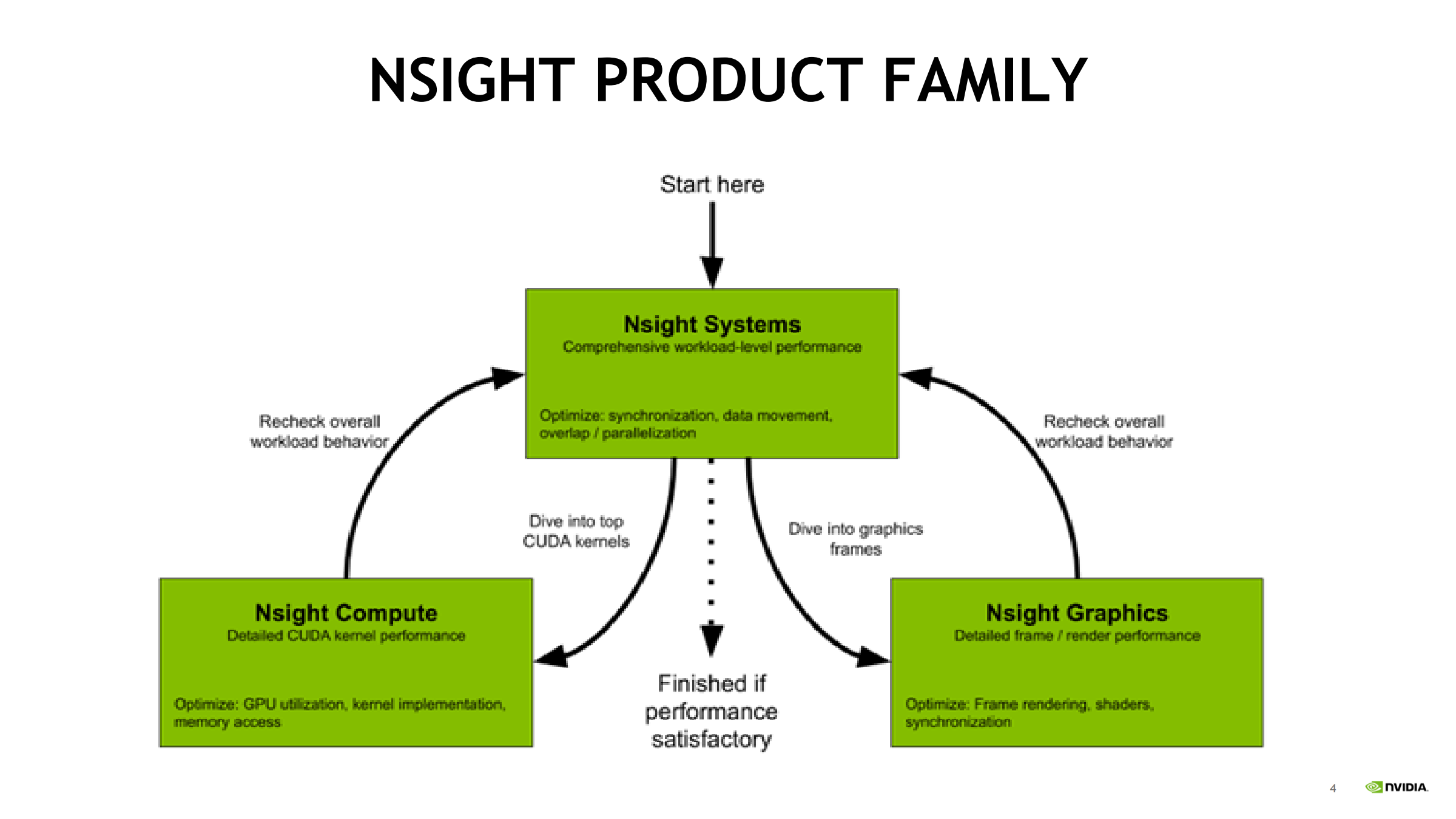
- 从 Nsight Systems(Start here) 开始,看整体 workload 行为。
- Systems 指出 “top CUDA kernels” 或帧问题后:
- 计算/内核 → Nsight Compute
- 图形/渲染 → Nsight Graphics
- 优化后必须回到 Systems 复核整体行为:GPU idle 是否减少、overlap 是否改善。
“Workload 行为”到底指什么
workload 行为 = 全局视角看应用“怎么跑”(谁在忙、谁在等、哪里空、哪里堵),而不是某个 kernel 的微观指标。
通常包括:
- CPU 行为
- 线程是否忙、是否大量等待(锁/IO)
- CPU 是否成为瓶颈
- GPU 行为
- GPU 是否持续有活干
- 是否出现大段空闲(idle gaps)
- CPU↔GPU 交互
- kernel launch 是否密集
- 同步调用(如 cudaDeviceSynchronize)是否频繁
- 数据移动
- H2D/D2H 拷贝是否多
- 是否与 kernel overlap
- 是否被 PCIe/拷贝队列卡住
- 并行性/重叠
- 计算与拷贝是否重叠
- 多 stream 是否真正并行
- 整体吞吐/延迟模式
- 吞吐型(一直跑满)
- 延迟型(一段一段卡住)
04. Profile → Inspect & Analyze → Optimize(先测量再优化)
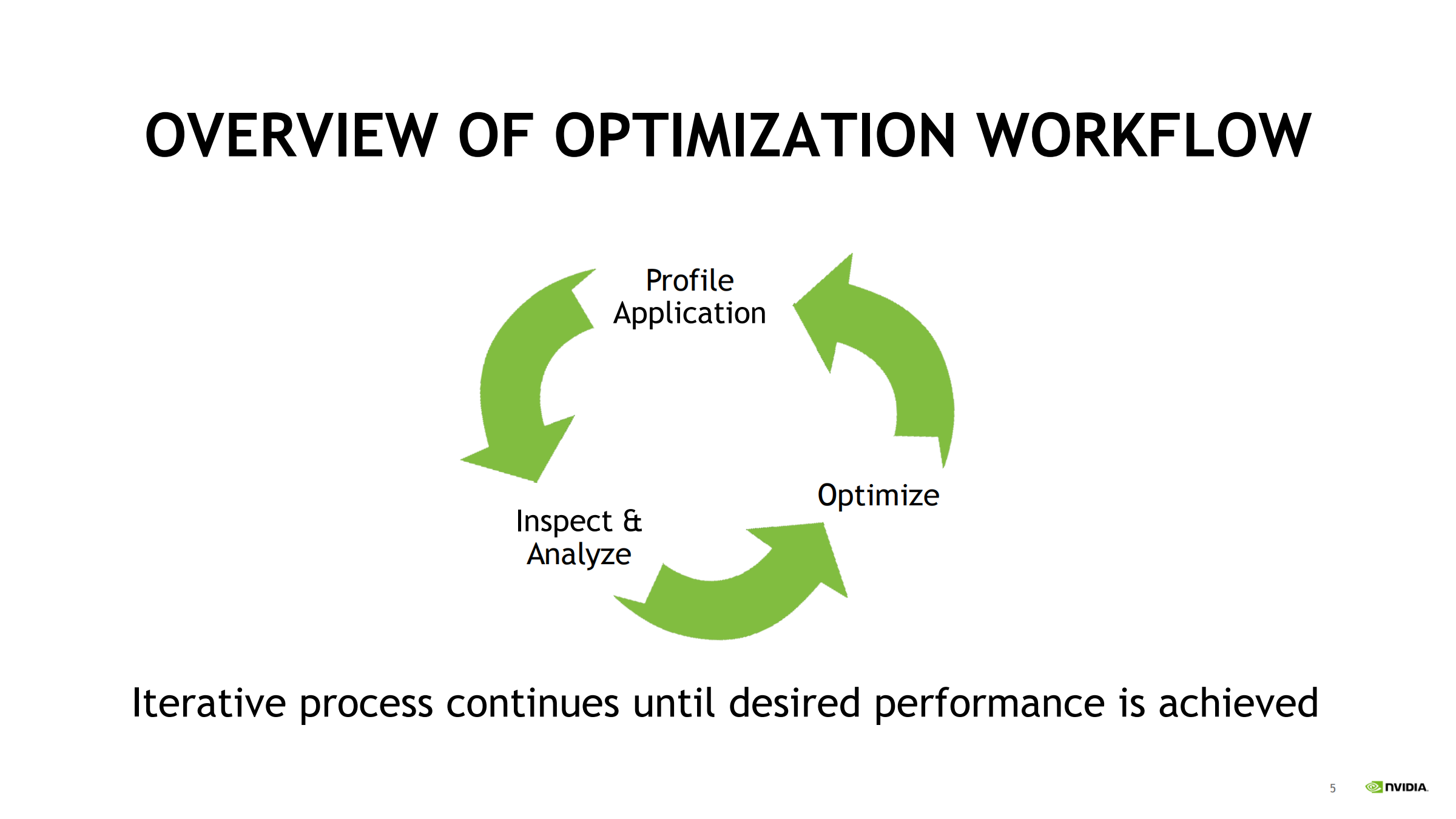
- 避免过早优化:先用 profiler 把瓶颈归类到同步/启动开销/访存/算力/调度等。
- 每轮优化后要重新 profile:瓶颈可能迁移(如访存优化后变 compute bound)。
05. Nsight Systems:核心输出与价值

核心输出:时间线(Timeline)
把以下内容放在同一时间轴:
- CPU 线程状态
- CUDA API
- GPU kernel/memcpy
- 库调用(cuBLAS/cuDNN/TensorRT 等)
- 同步/等待
价值:算法视角定位系统瓶颈
你能看见:
CPU/GPU 是否有空洞(unused time)
是否被同步阻塞
数据搬运是否遮蔽计算
aunch 是否跟不上
适用场景
多线程、多 GPU、深度学习训练/推理、图形+CUDA 混合等。
策略:先用 Systems 找整体机会点,再决定是否下钻到 ncu。
06. Nsight Systems 能“看见”的东西(能力清单)

- CUDA API 与 kernel 关联
- cuBLAS/cuDNN/TensorRT 等库 trace
- OpenACC
- 图形 API(Vulkan/OpenGL/DX)
- OS 线程/IO
- NVTX(重点):把业务逻辑标到时间线上(epoch/iter/layer/阶段),避免只看到一堆 kernel 名
07. 多线程/多 GPU 时间线怎么读(概览)
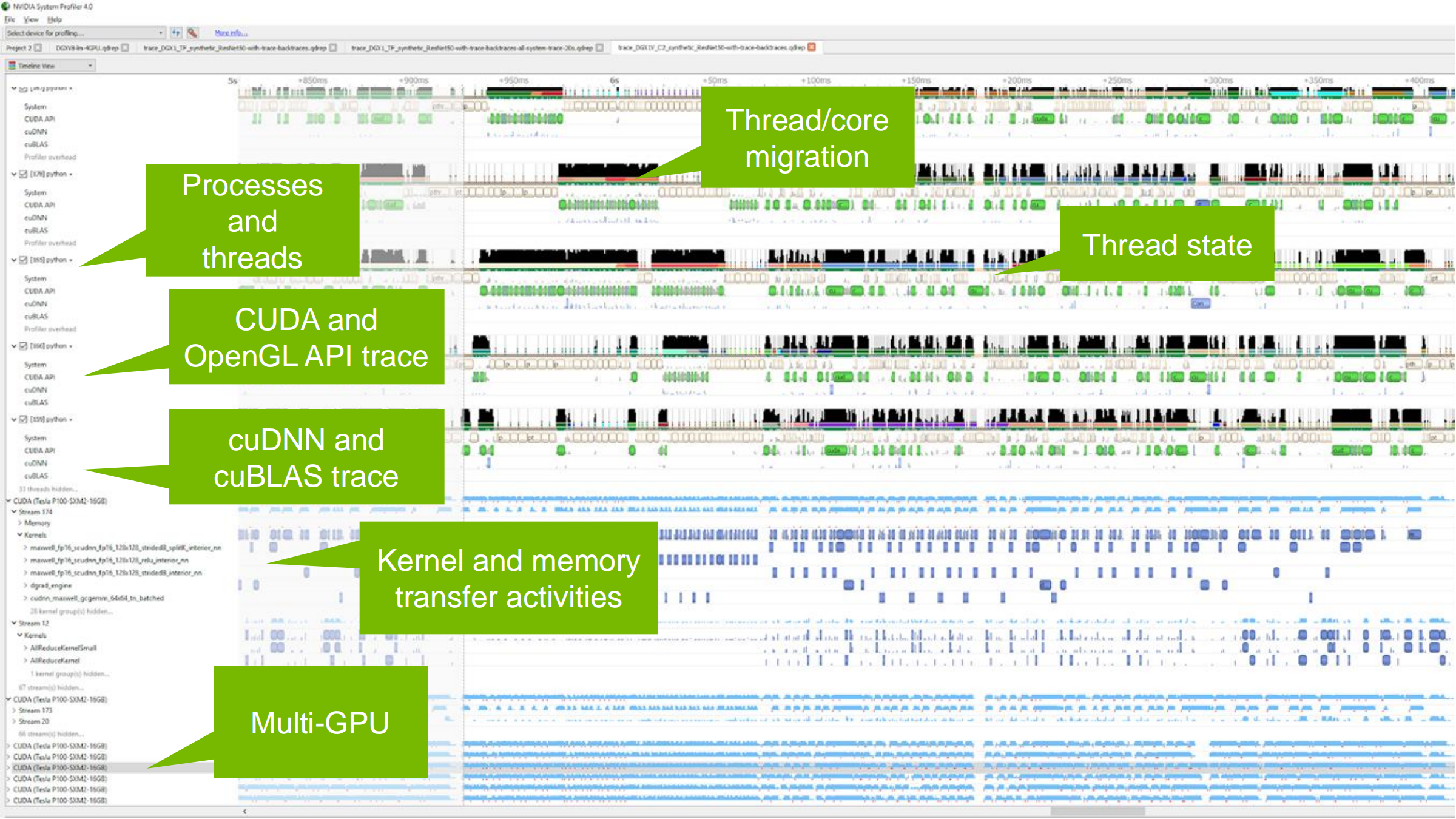
Nsight Systems 可跟踪并显示:
- Processes and threads:进程与线程活动
- CUDA / OpenGL API trace:调用轨迹、CUDA 与 OpenGL 同时工作
- cuDNN / cuBLAS trace:库调用跟踪
- Thread state:线程 Running/Sleeping/Waiting
- Thread/core migration:线程跨核迁移与负载均衡
- Kernel / Memory 活动:kernel 与内存传输,是否 overlap
- Multi-GPU:每个 GPU 的 workload 与 GPU 间传输协作
08. CPU Threads 时间轴:关注点(线程活动概览)

重点看四类信息:
- 线程跑在哪个 CPU 核心上,对应 CPU 利用率/忙闲
- 线程状态与状态切换(Running/Sleeping/Waiting 等)
- OS 运行时库调用:pthread、file I/O 等
- GPU/加速 API 调用轨迹:CUDA、cuDNN、cuBLAS、TensorRT 等
→ 用于对齐 CPU 侧调用与 GPU 侧执行、找瓶颈
09. 放大后如何读 CPU 侧活动(从上到下)

- 顶部黑色条/黑块:Avg CPU core utilization(越黑越忙)
- CPU core:线程实际运行在哪些核心上
- Thread state:
- 灰色:等待/阻塞(waiting)
- 有颜色:活动/运行
- 不同颜色块:区分不同 runtime/库调用(如 pthread 等)
→ 判断时间花在“等锁/等待”还是“真正执行”
10. OS Runtime Libraries 层:怎么用来定位问题

- 通过 pthread_cond_wait、sem_wait 等调用轨迹找线程阻塞区段与原因(等锁/等条件变量/等信号量)。
- 用阻塞点判断是否存在 不必要或重复同步(redundant synchronizations)。
- 对齐 CUDA API / cuDNN kernel 执行:判断时间浪费在 CPU 同步还是 GPU kernel。
11. Backtrace(调用栈):追根溯源 CPU→GPU
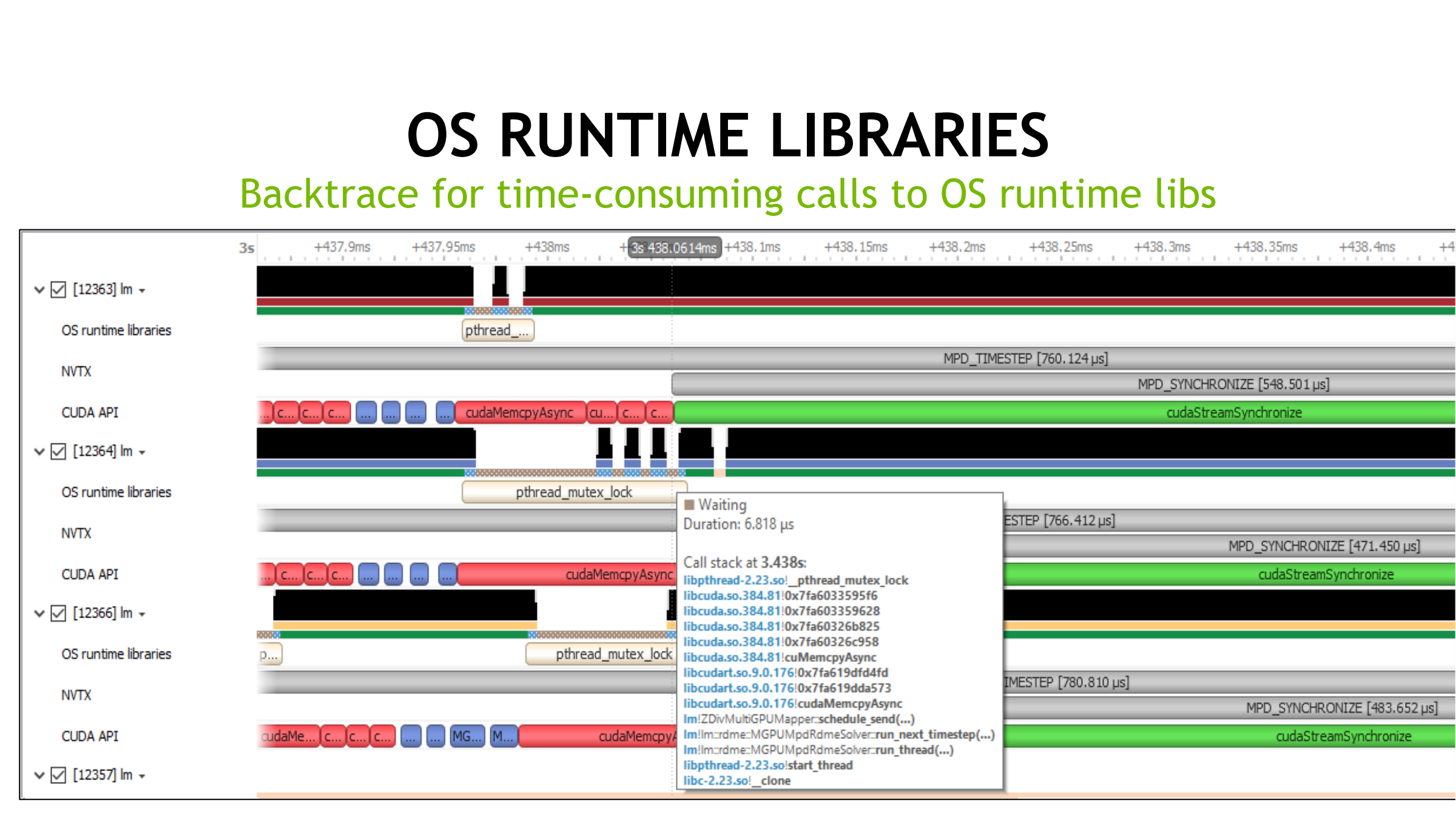
- 对 OS runtime 耗时调用(如 pthread_mutex_lock)看 backtrace:
- 知道是谁在 CPU 侧造成阻塞/高开销
- 对 CUDA API 也可做回溯:
- kernel 启动开销(launch overhead)
- kernel 来自用户代码或 cuDNN/TensorRT 等库
- 对 Memory 操作(memcpy/malloc 等)也能追踪:
- 谁在 CPU 侧发起
- 发起/调用开销
目的:把 Memory 与 Kernel 的时间轴与 CUDA 调用链(依赖)组织起来,明确“谁调用了谁、哪里花了时间”。
12. CUDA API 这一层:CPU 侧发起与 GPU 侧执行对齐
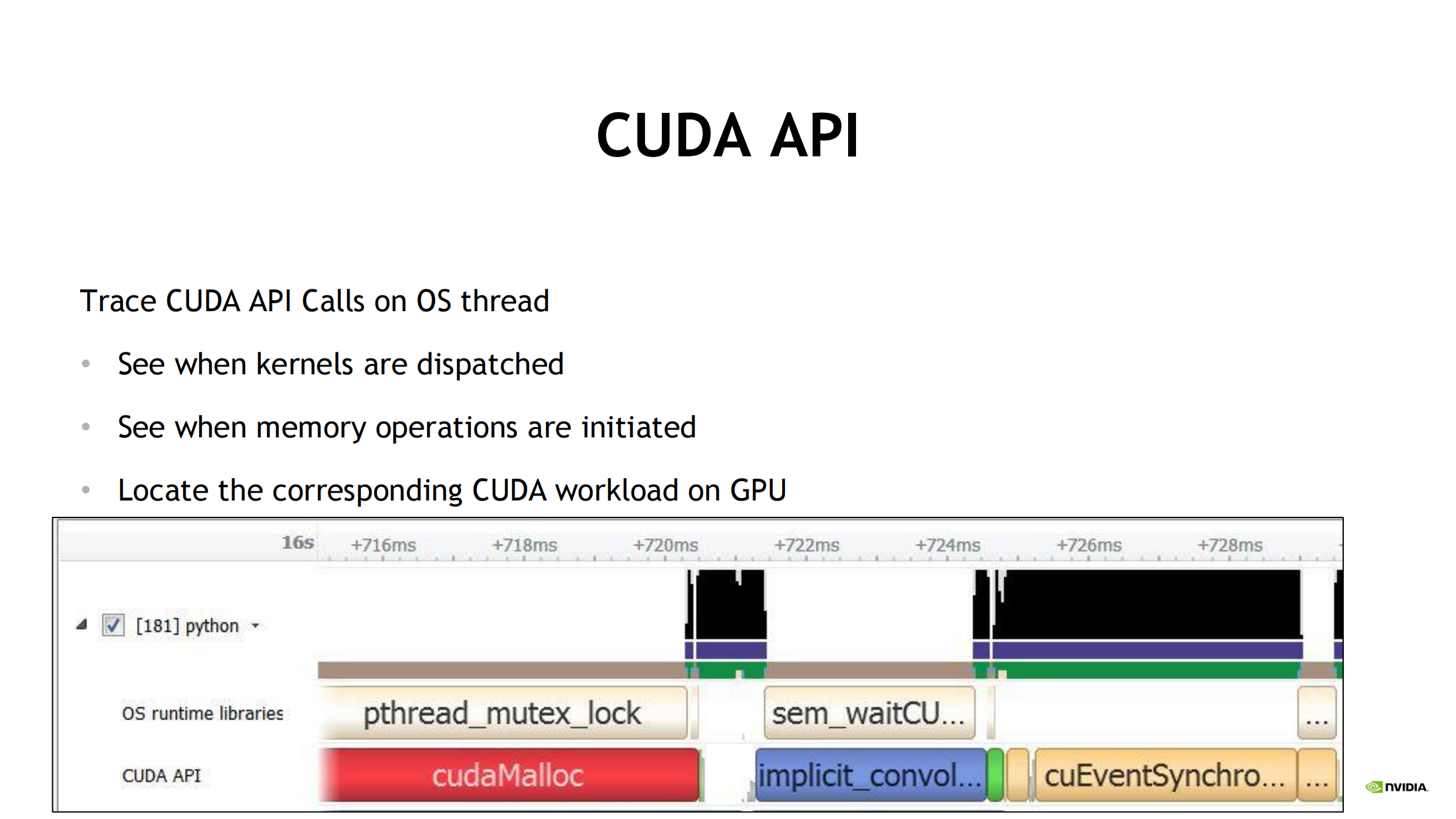
- Trace CUDA API Calls on OS thread:
- 看到什么时候调用 cudaMalloc、cudaEventSynchronize 等
- 对齐下游 GPU workload:
- kernel 何时 dispatch、启动开销
- 内存操作何时发起、发起开销
- 支持展示 CUDA 调用关系(调用链/组织结构),便于追根溯源。
13. GPU Workload 视图:看 GPU 上到底在跑什么
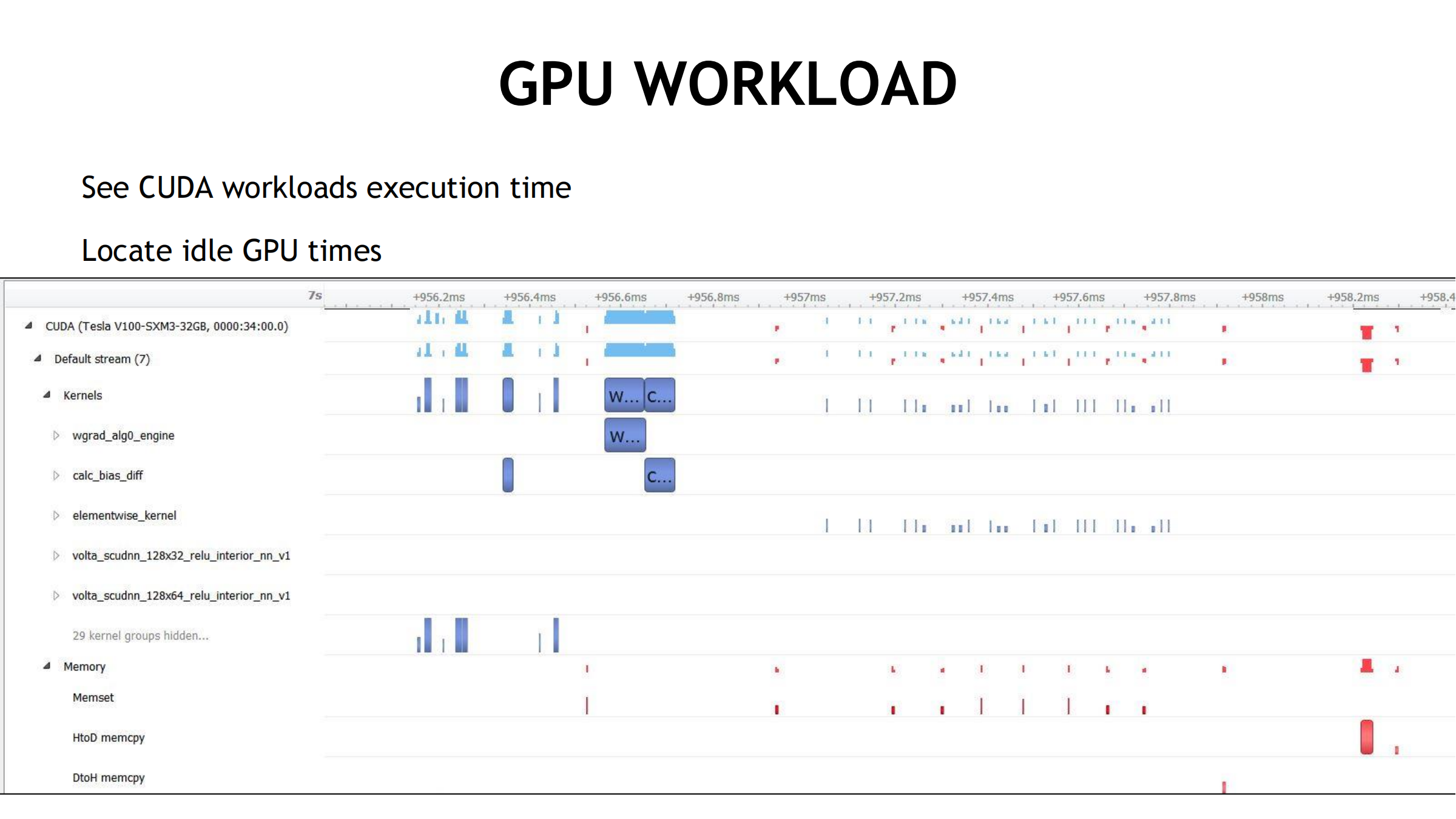
- 查看 CUDA workloads 的执行时间:开始顺序、持续时长
- 定位 GPU idle:找时间线空档,判断原因:
- CPU 同步/等待
- 发射不够
- 数据传输
- 依赖等待
14. GPU Workload 汇总曲线:覆盖率与内存操作强度
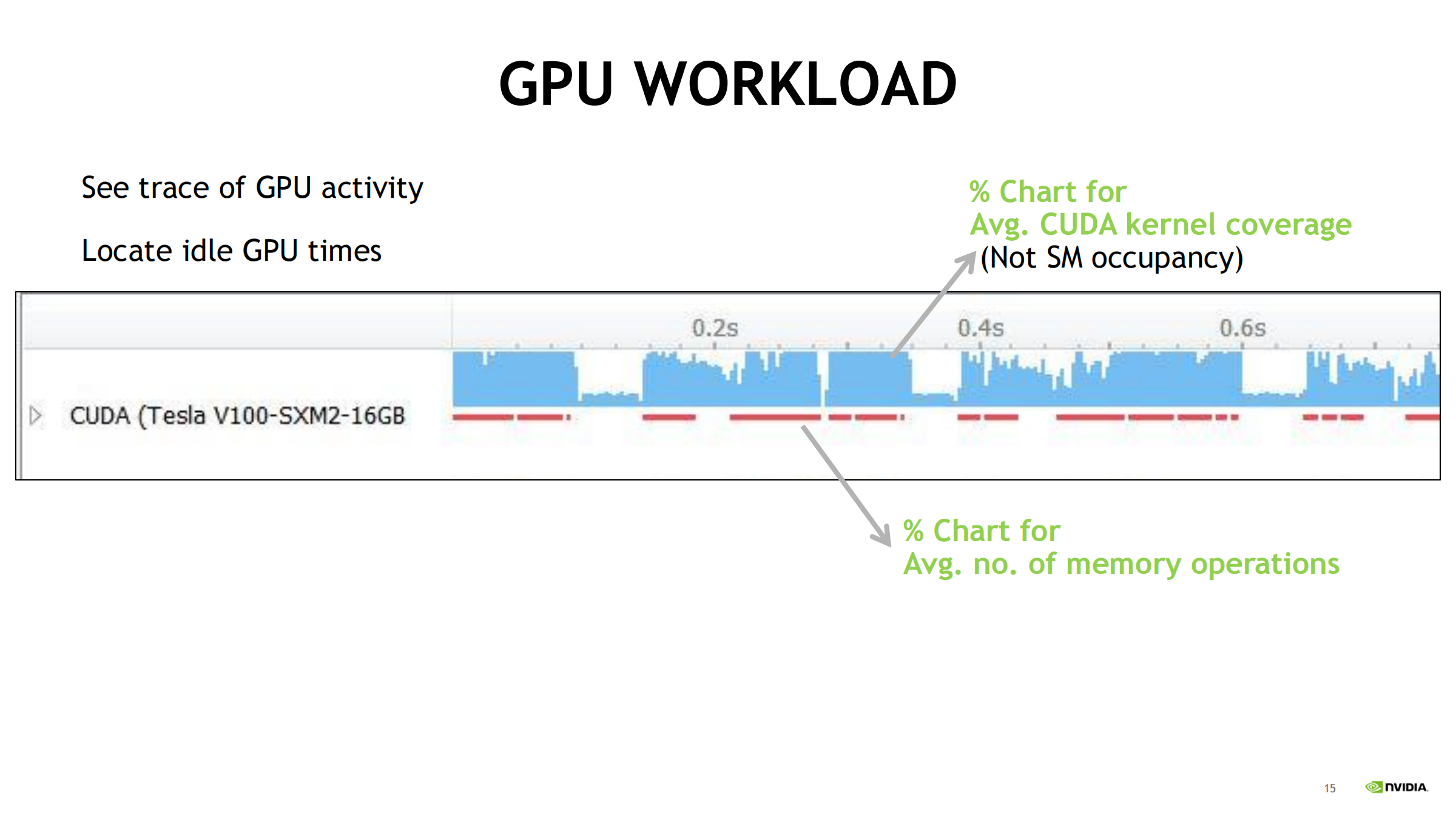
- 蓝色面积:Avg. CUDA kernel coverage(注意:不是 SM occupancy)
- 越高:GPU 时间大多在执行 kernel
- 越低:短 kernel/间隙多,GPU 可能空闲
- 红色:Avg. number of memory operations(内存操作次数/强度)
- 还能关联 CPU 上的 launch 与 GPU 上的执行:
- 发起在 CPU,执行在 GPU
- 易定位 CPU 发射/同步、GPU idle、内存操作过多
15. 依赖分析(Dependency Analysis):因果链对齐

- 同时展示 OS runtime、CUDA API、GPU kernel/stream/memory。
- 选中某个 CUDA API 或 kernel,工具高亮上游/下游事件:
- cause & effect(因果)
- 哪个依赖卡住了执行
- GPU idle 是否源于 CPU 同步/等待或发射延迟
16. NVTX Instrumentation:给时间线加“业务语义”

为什么需要 NVTX
- 没有 NVTX 时,只看到一堆 kernel/底层名字,很难映射到算法流程。
NVTX 能带来什么
- 用 range/marker 标注 epoch/iteration/batch/阶段
- 建立 kernel/调用 ↔ 算法阶段对应关系
- 更快发现热点与瓶颈
17. NVTX 打点用法(C/C++ 与 Python)

C/C++
- #include “nvToolsExt.h”
- 调用 NVTX API(push/pop range 等)
- 链接:-lnvToolsExt
Python
- Python 也支持 NVTX 打点
- 生态支持:
- CuPy profiler/NVTX 支持
- TensorFlow 的 NVTX/性能 logging 插件思路(把高层算子范围标进 timeline)
目的:从算法角度理解时间分布(DataCopy/Forward/Backward 等),快速定位热点/瓶颈。
18. NVTX 示例(Example)
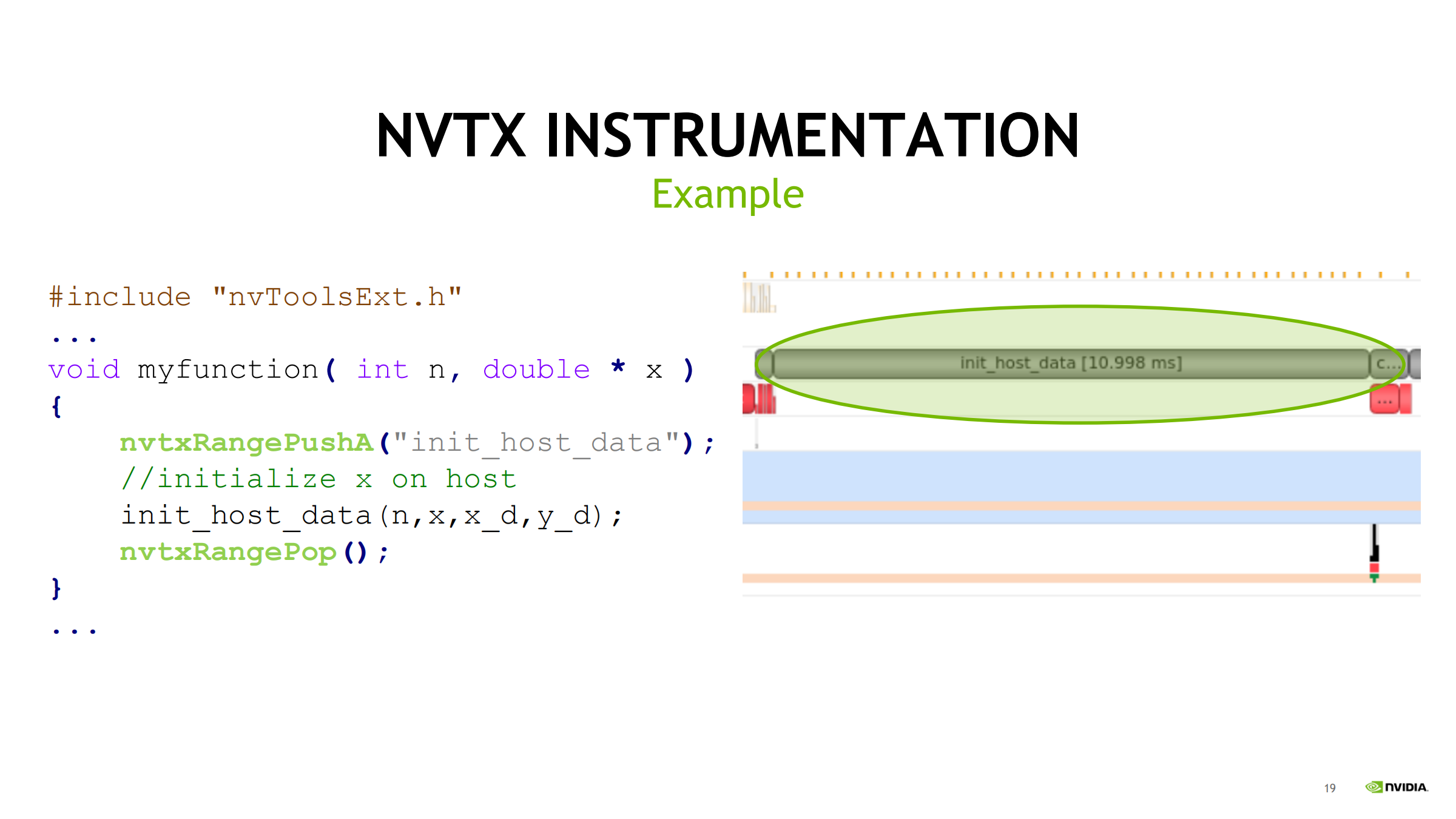
- 代码思路:用成对 NVTX range 包住目标代码段
- nvtxRangePushA(“init_host_data”)
- nvtxRangePop()
- 效果:timeline 上出现名为 init_host_data 的区段条,显示持续时间(如 ~10ms),把 profiler 底层事件与代码模块对应起来。
19. Nsight Compute(ncu):kernel profiler 概览

- 新一代 kernel profiler,面向单个/少量 kernel 深度分析
- 核心报表:
- SOL(Speed Of Light)
- Memory/Compute/Scheduler 等 sections
- 支持 baselines 对比(优化前后)
- 工具形态:
- UI:nv-nsight-cu
- CLI:nv-nsight-cu-cli
- 架构适配:Pascal/Volta/Turing/Ampere 等(不同版本支持范围可能变化)
20. SOL / Memory breakdown:怎么读“为什么 bound”
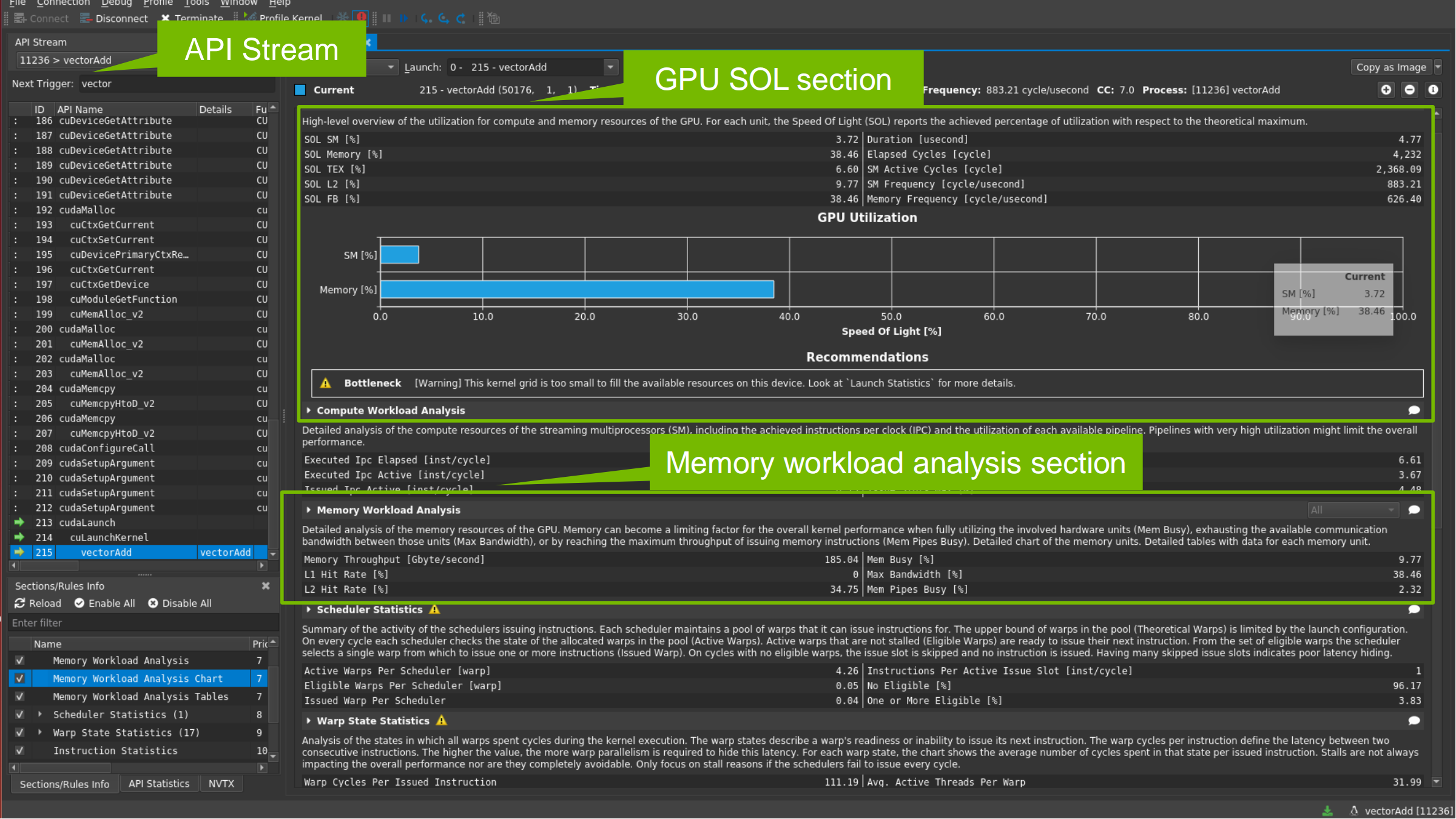
- SOL breakdown / Memory breakdown 表格会把“为什么 compute/memory/latency bound”拆到具体指标:
- DRAM throughput
- L2 hit
- pipe utilization 等
- 读法:
- 先看最上面的 GPU Utilization bar
- 再看 breakdown 找“最高的一项”作为首要线索
Nsight Compute UI:API Stream + SOL + Workload
- 左侧:API Stream(CUDA API / kernel 历史列表)
→ 点选 kernel 进入分析 - 上方:GPU Utilization(SOL 视角:SM/Memory 利用率)
- 下方:Workload 分析区(Memory/Compute 等)
- 常用 Full Analyze
21. API Stream:精准抓取目标 kernel

- 可跳转到:
- 下一个 kernel
- 下一个 CUDA API
- 下一个 range start/stop
- Next Trigger 支持正则过滤(如只抓名字含 foo 的 kernel)
- 实践:先用 nsys 找热点 kernel 名 → 再用 ncu Next Trigger 精准抓一次/几次执行
22. ncu 三层结构:Event → Metric → Section

- Event:硬件可计数事件(cache miss、内存请求等)
- Metric:由一个或多个 event 计算得到(如 gld_efficiency)
- Section:按主题组织 metrics(Memory/Compute/Scheduler 等)
策略:先看 section 高层结论(SOL/Memory/Compute/Scheduler),再按需深入具体 metrics。
23. Events / Metrics:与 nvprof 的迁移提醒


- ncu 的 Events 仍是硬件事件,但命名/定义与 nvprof 不完全一致
- 需要用官方映射表对齐:
- nvprof events/metrics → ncu 对应项
- 有些 nvprof 指标在 ncu 中被舍弃,也有新增
- 可用 query 列出某 GPU 平台支持哪些 metrics
24. SOL(Speed Of Light)三种典型判定
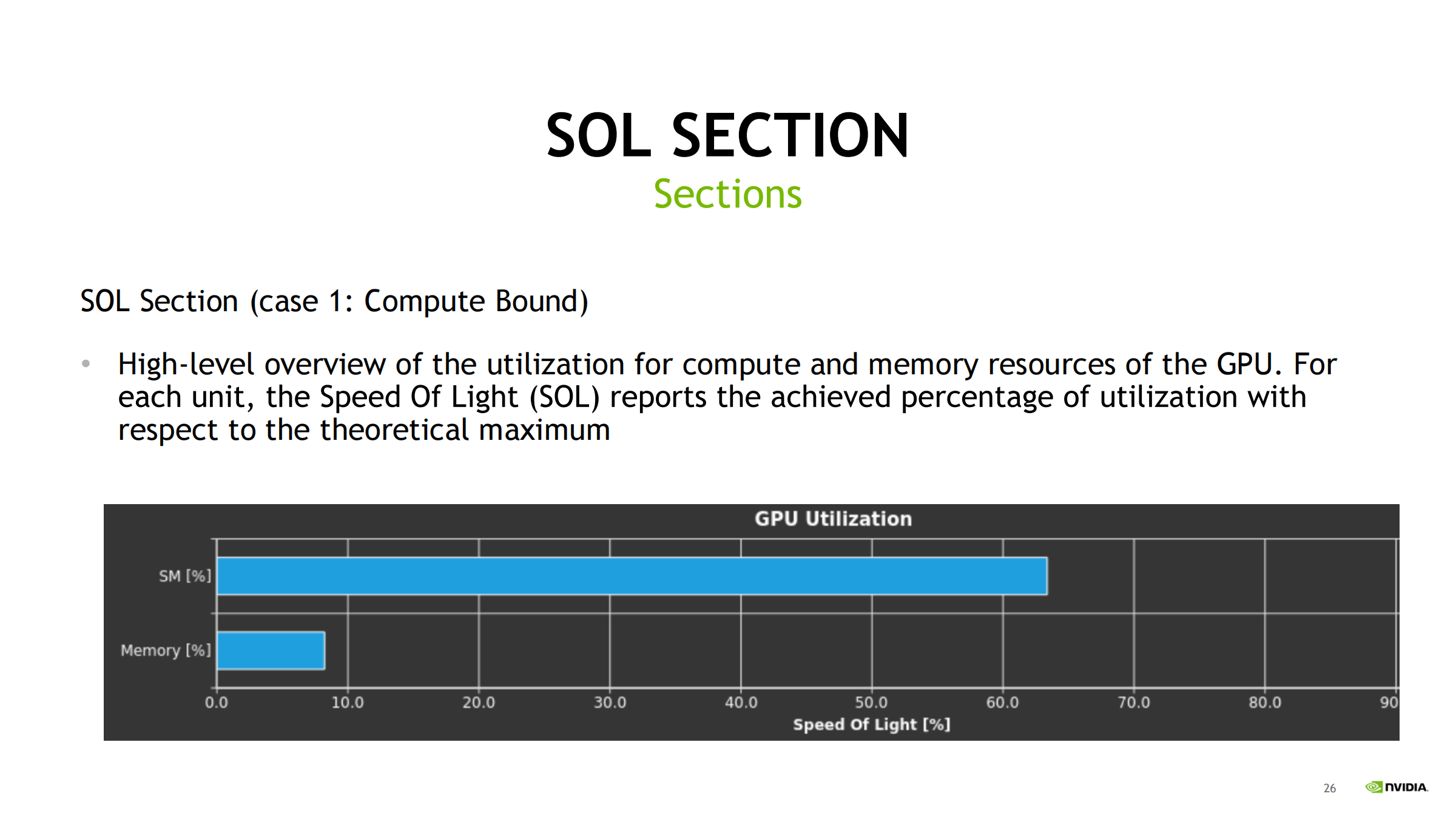
Case 1:Compute Bound
- SM/算力利用率高,Memory 相对低
- 优化方向:
- 减少指令
- 提高 ILP
- 更合适的数学指令/数据类型(如 Tensor Core)
- 降低分支与依赖

Case 2:Memory Bound
- Memory 利用率高,SM 利用率低
- 受限于带宽或访存效率
- 优化方向:
- coalescing
- 提高缓存命中
- shared memory/ldg/向量化加载
- 减少无用读写
SOL 汇总逻辑:SM% 与 Memory% 常取各自候选 metrics 中的最大值作为展示项(如 DRAM throughput = 81.56% → 成为 Memory SOL)。鼠标悬停可看 metric 全名。

Case 3:Latency Bound
- SM 不高、Memory 也不高 → 单元都在“等”
- 常见原因:
- 并行度不够(活跃 warps 少)
- stall/依赖等待多
- 优化方向:
- 增加并行度隐藏延迟(更多 warps)
- 减少串行依赖链/同步/分歧
- 改善内存局部性

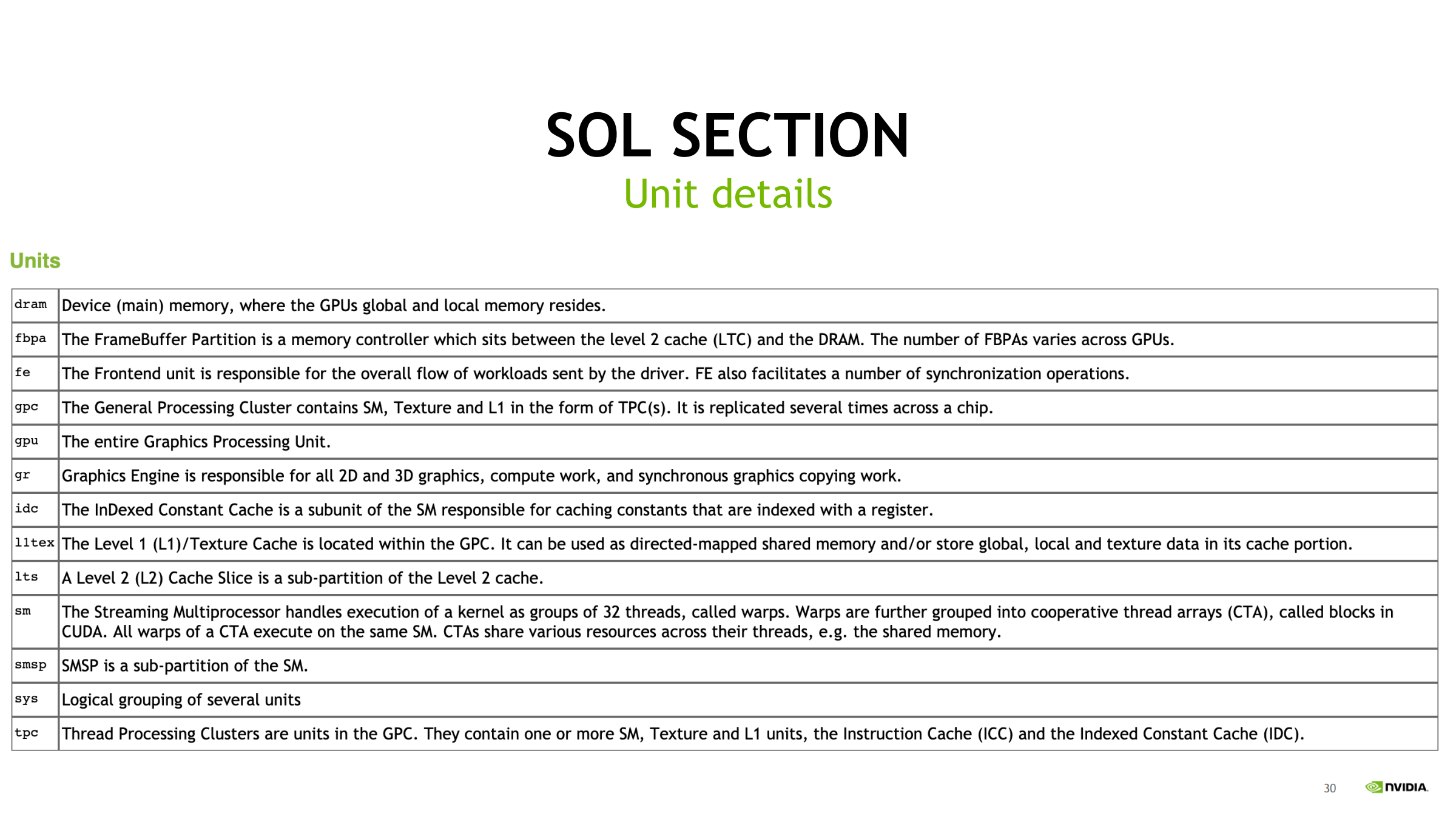
Unit details:读懂 SOL 单元缩写
- SOL 里会出现 L2、TEX、TPC、GPC 等单位缩写
- 实践:
- 某单位 SOL 很高 → 去对应 workload section(Compute/Memory)看细指标
- 不认识就查 unit details 表
25. Compute Workload Analysis:SM 内部“忙在哪”


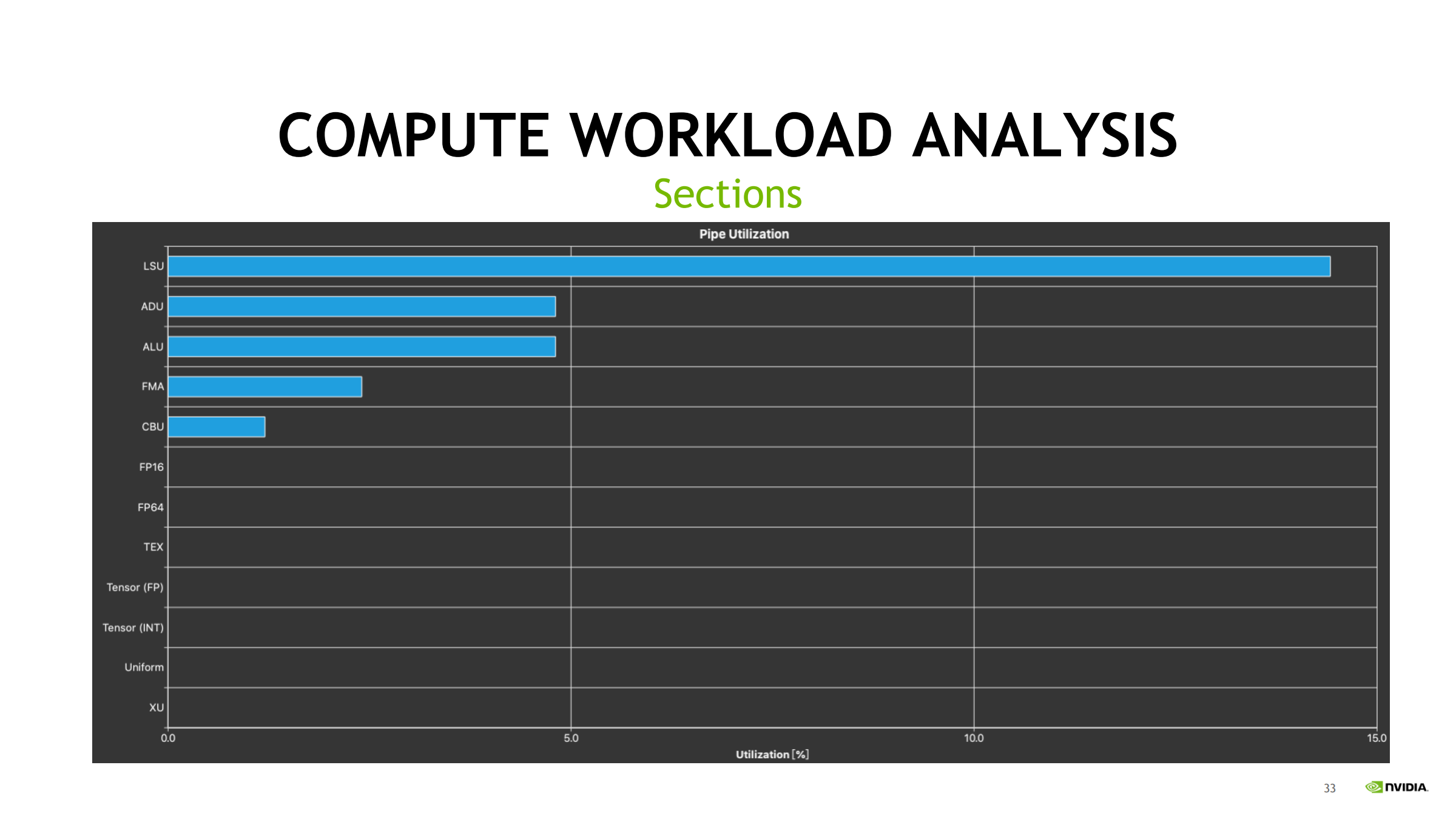
- 关注:
- IPC(每周期指令数)
- Pipe utilization(ALU/FMA/Tensor/SFU/LDST 等)
- 诊断直觉:
- 某 pipe 利用率很高 → 吞吐瓶颈
- IPC 低且没有明显 busy → 依赖/调度/分歧/寄存器压力
- 优化方向:
- 降低热点 pipe 压力、算子融合/重排
- 使用更高吞吐指令/路径(如 Tensor Core)
- 降低分支与寄存器压力
26. Scheduler Statistics:warp 是否“喂得饱”
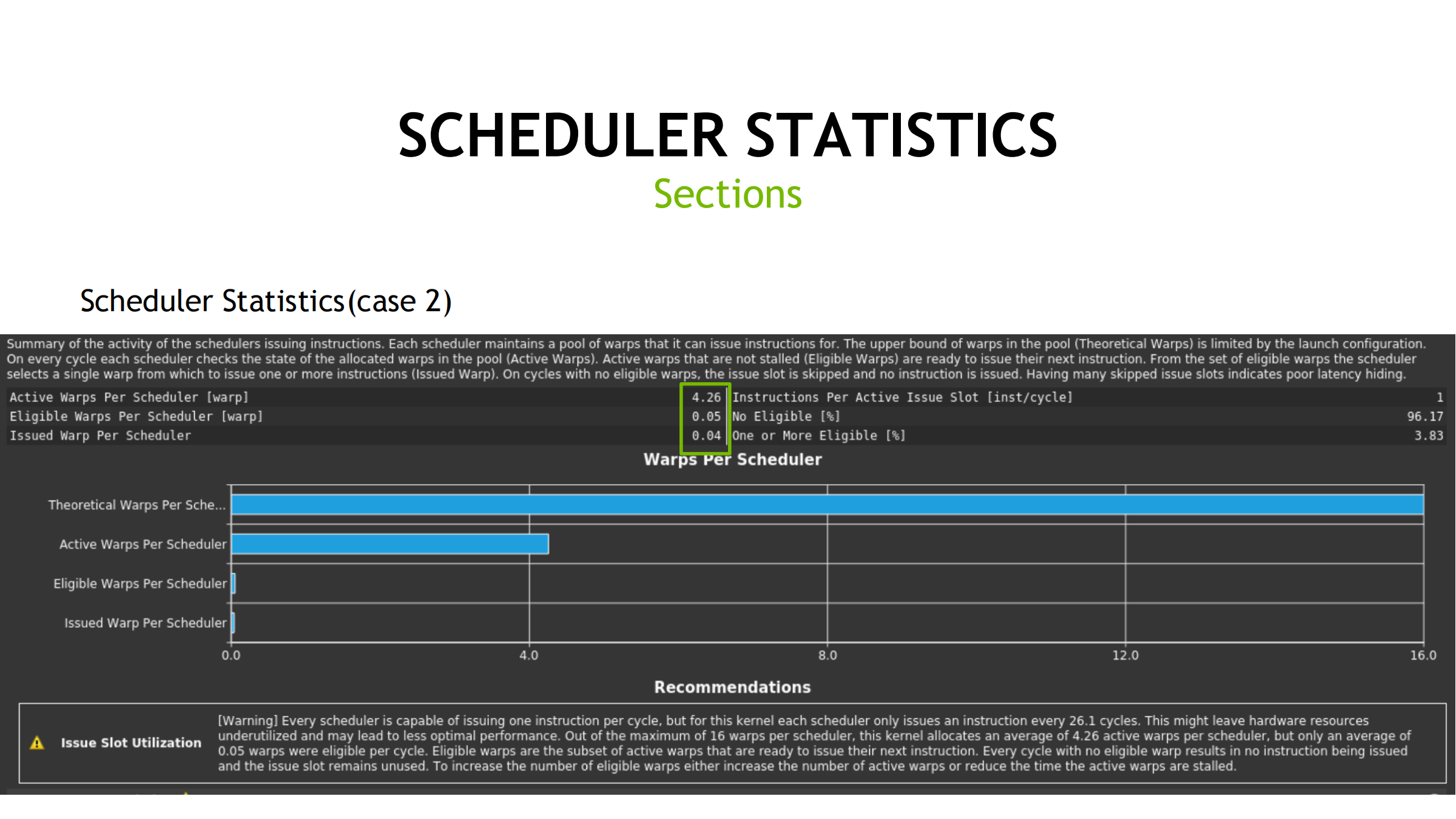
关键指标:
- Theoretical Warps Per Scheduler
- Active Warps Per Scheduler
- Eligible Warps Per Scheduler
- Issued Warps Per Scheduler
直觉:
- Active 多不代表快;Eligible/Issued 才关键
- Eligible 低 → 依赖等待(memory/scoreboard)
- Eligible 高但 Issued 低 → pipe 忙/结构冲突
27. Warp State Statistics:stall 大类与用法

五大类 stall:
- Instruction Fetch(取指)
- Memory Dependency(内存依赖)
- Execution Dependency(执行依赖)
- Pipeline Busy(流水线繁忙)
- Synchronization Barrier(同步屏障)
用法:
- 先看占比最高的 stall reason
- 去 Memory/Compute section 交叉验证
- 例如 Long Scoreboard 常对应 global memory 延迟
- 再选择对应优化手段
28. Volta 示例:warp scheduler 心智模型
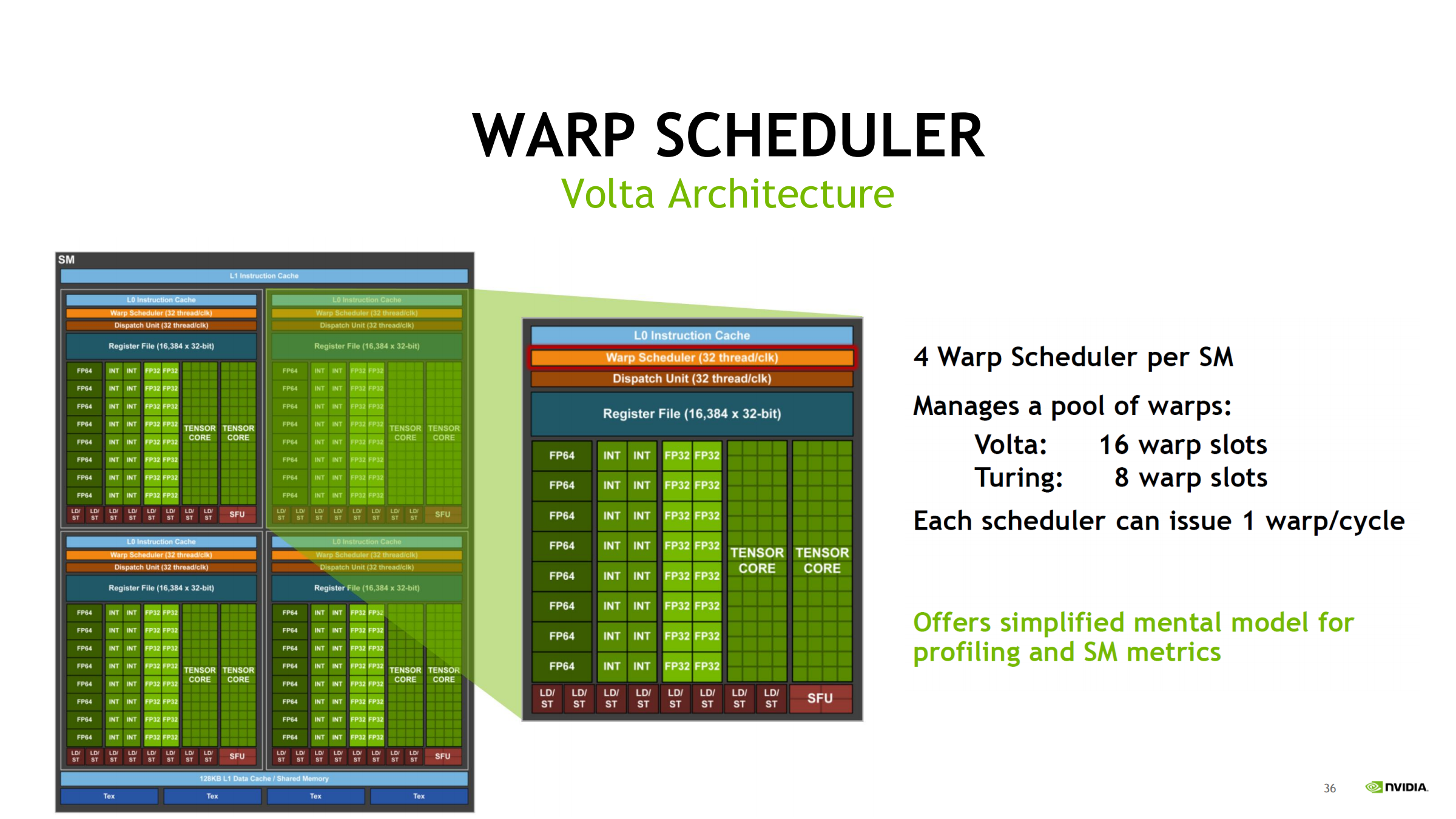
- 每个 SM 有 4 个 warp scheduler(Volta)
- 每个 scheduler 管理一池 warp slots
- Volta:16 slots
- Turing:8 slots
- 简化模型:每个 scheduler 每周期最多 issue 1 个 warp
→ 便于把 ncu scheduler 指标映射到硬件结构
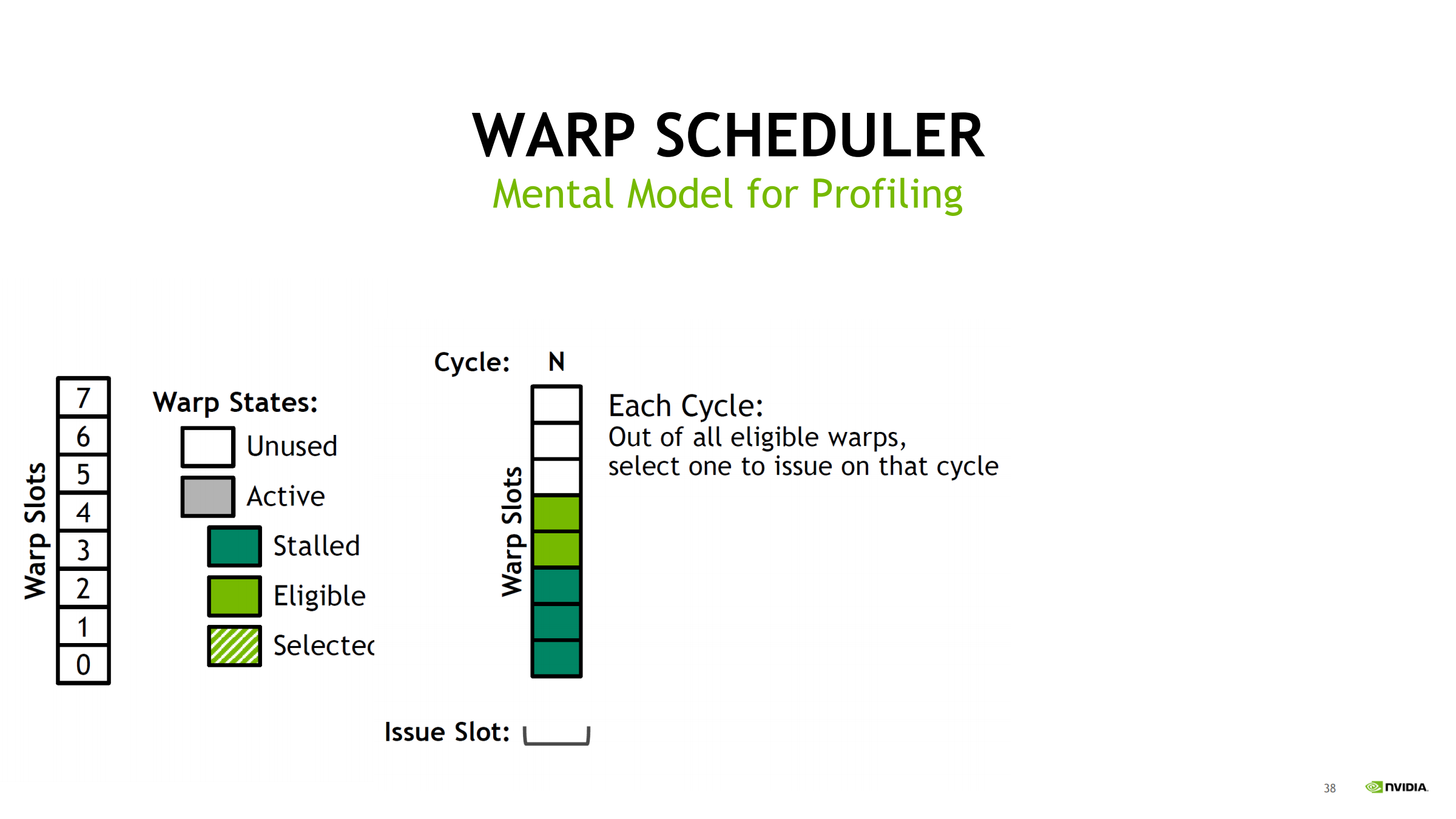
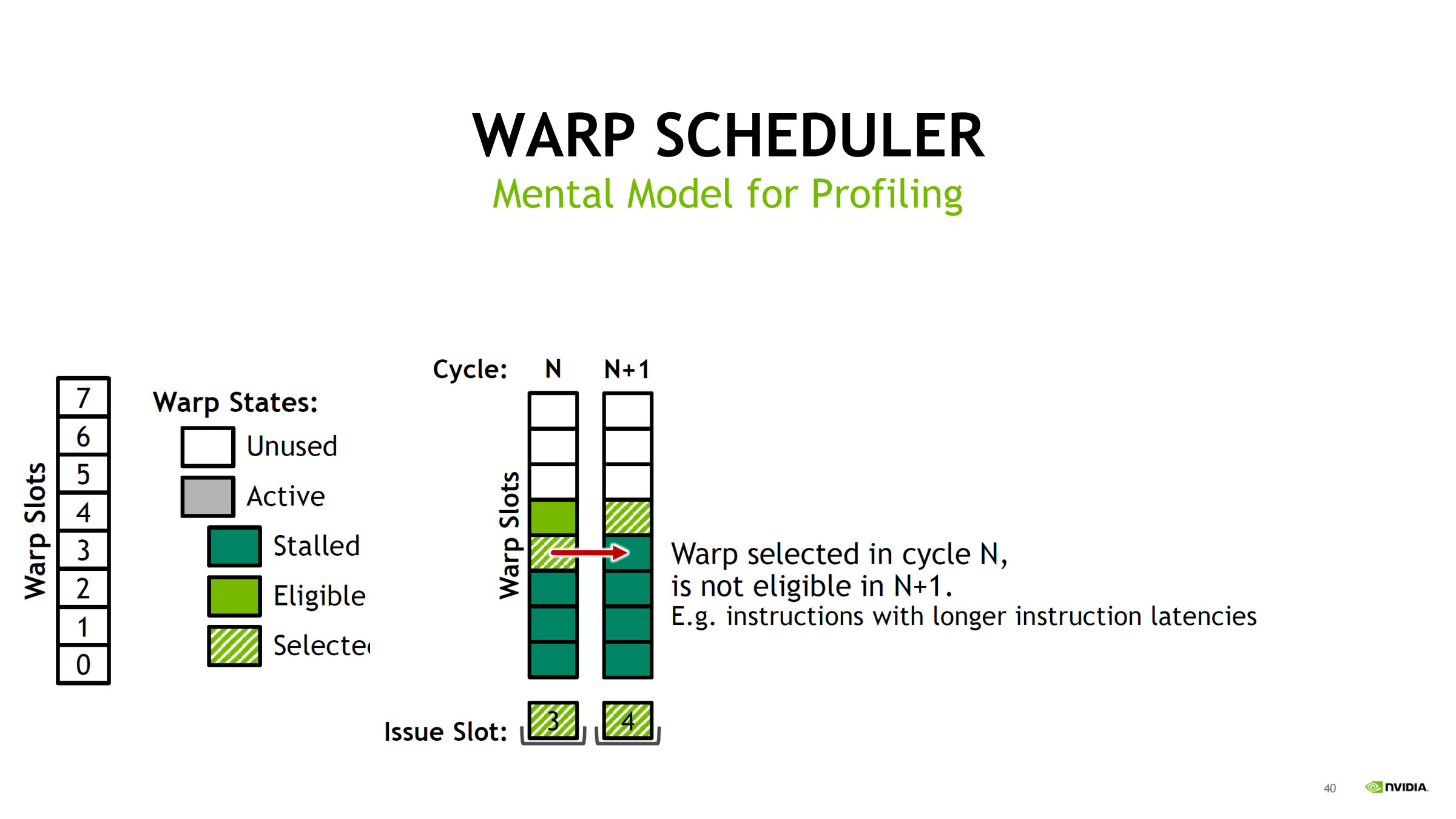
29. Warp slot 状态机(profiling 心智模型)

warp slot 可能状态:
- Unused
- Active
- Stalled
- Eligible
- Selected
包含关系:
- Selected ⊆ Eligible ⊆ Active
- Stalled 是 Active 中另一大块
读 ncu:
- Eligible 少 → 多数 warp 在 stalled
- Selected 少 → pipe 忙或结构限制
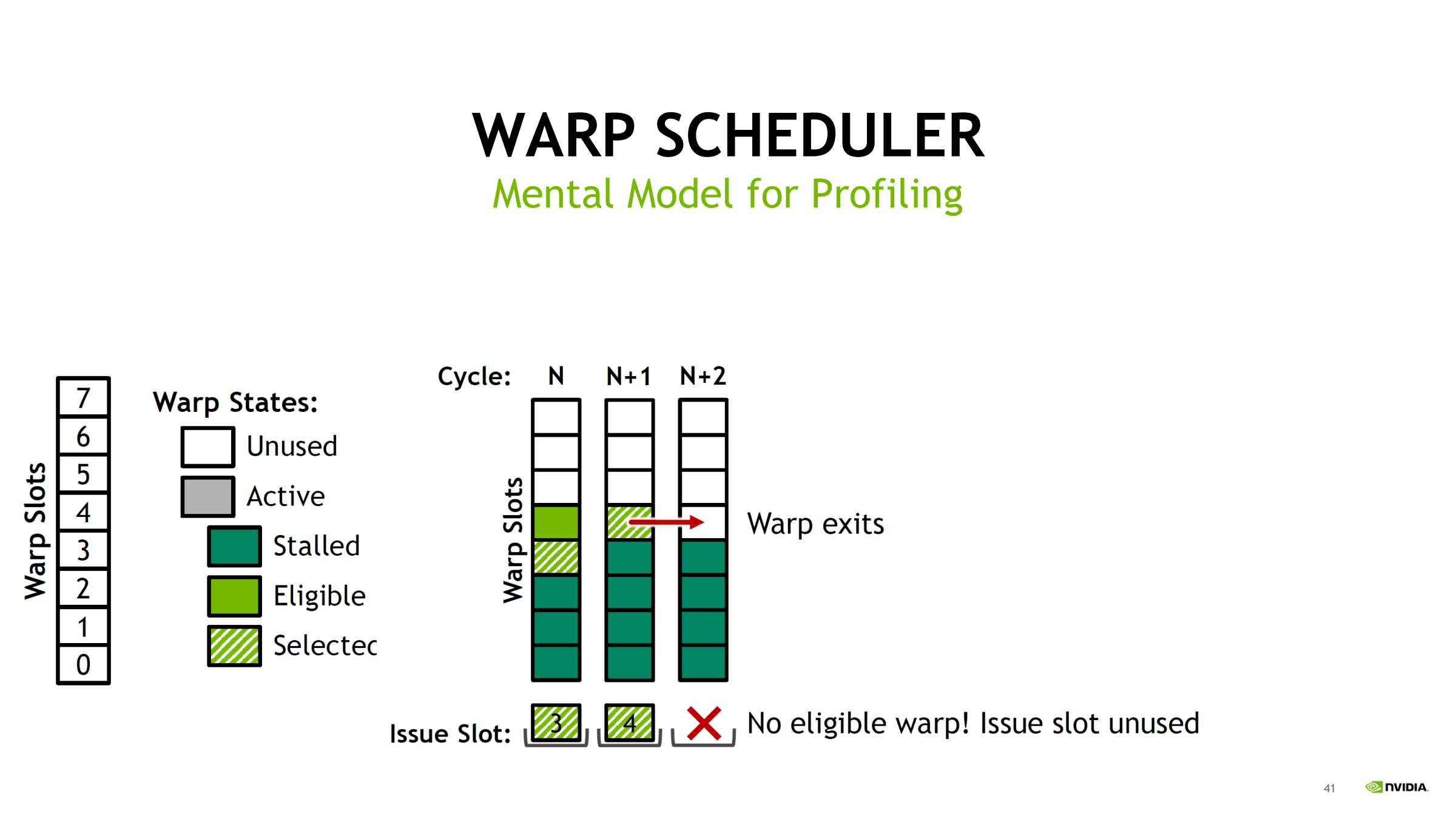
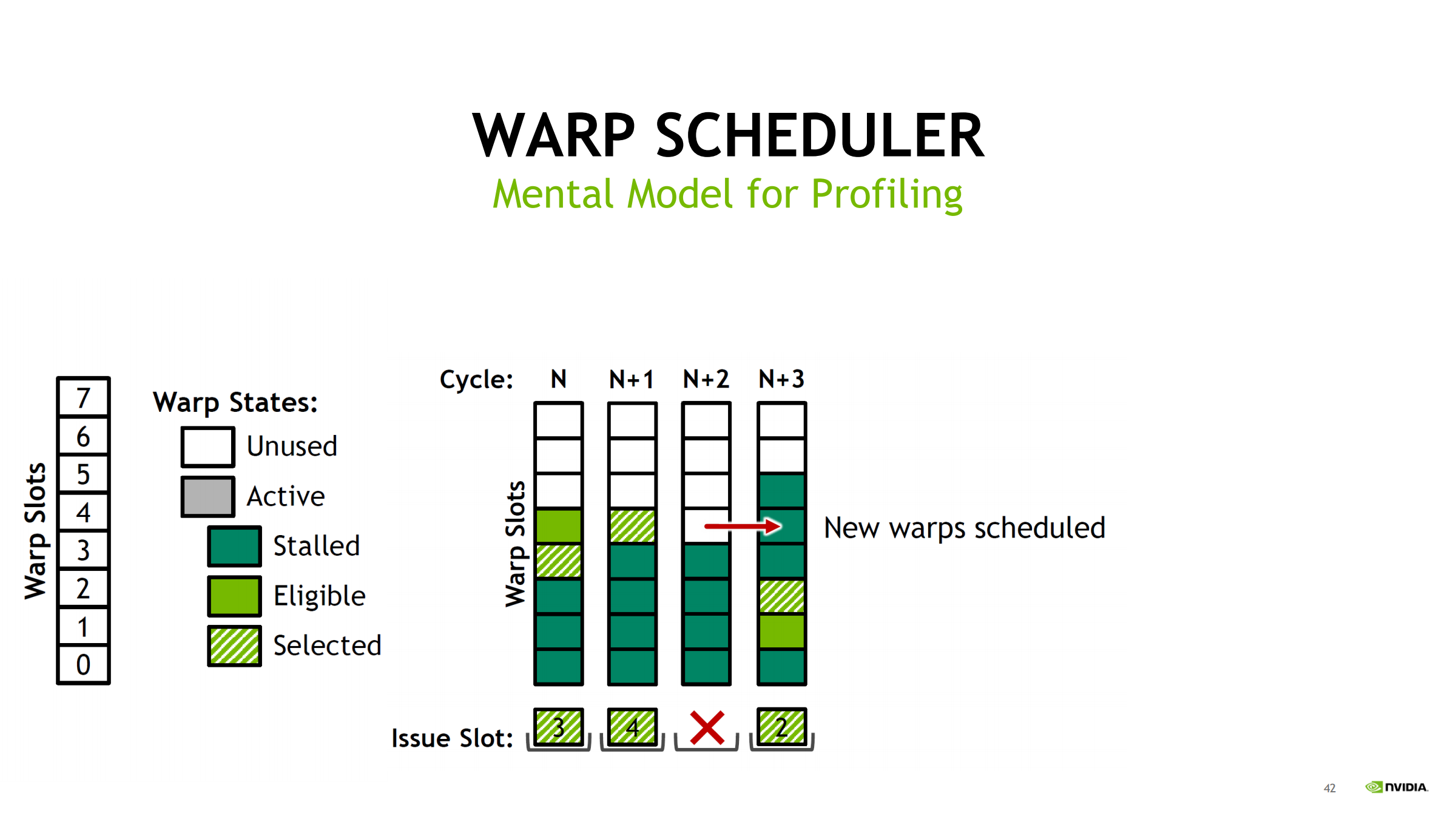
并补充 cycle 级直觉:
- 每个 cycle:从所有 eligible warps 中选一个 issue
- 被选中 warp 下一拍不一定 eligible(长延迟指令会让它暂时不可发)
- 若某拍无 eligible → issue slot unused(空转)
- 后续可通过 new warps scheduled 恢复;若长期空转 → 说明 stall 或并发不足是常态
30. Scheduler 指标如何从 slot 统计出来(示例推导)
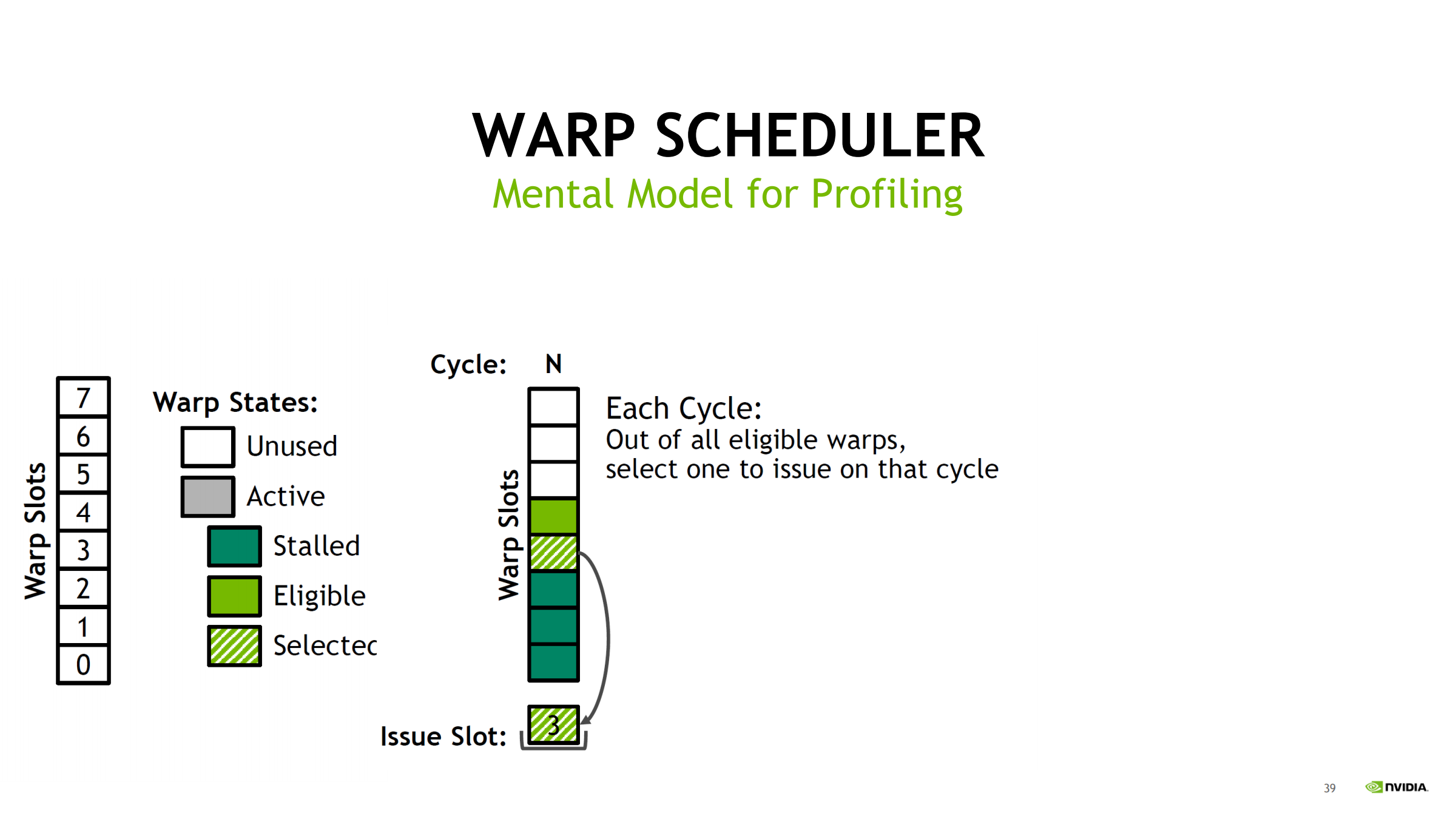
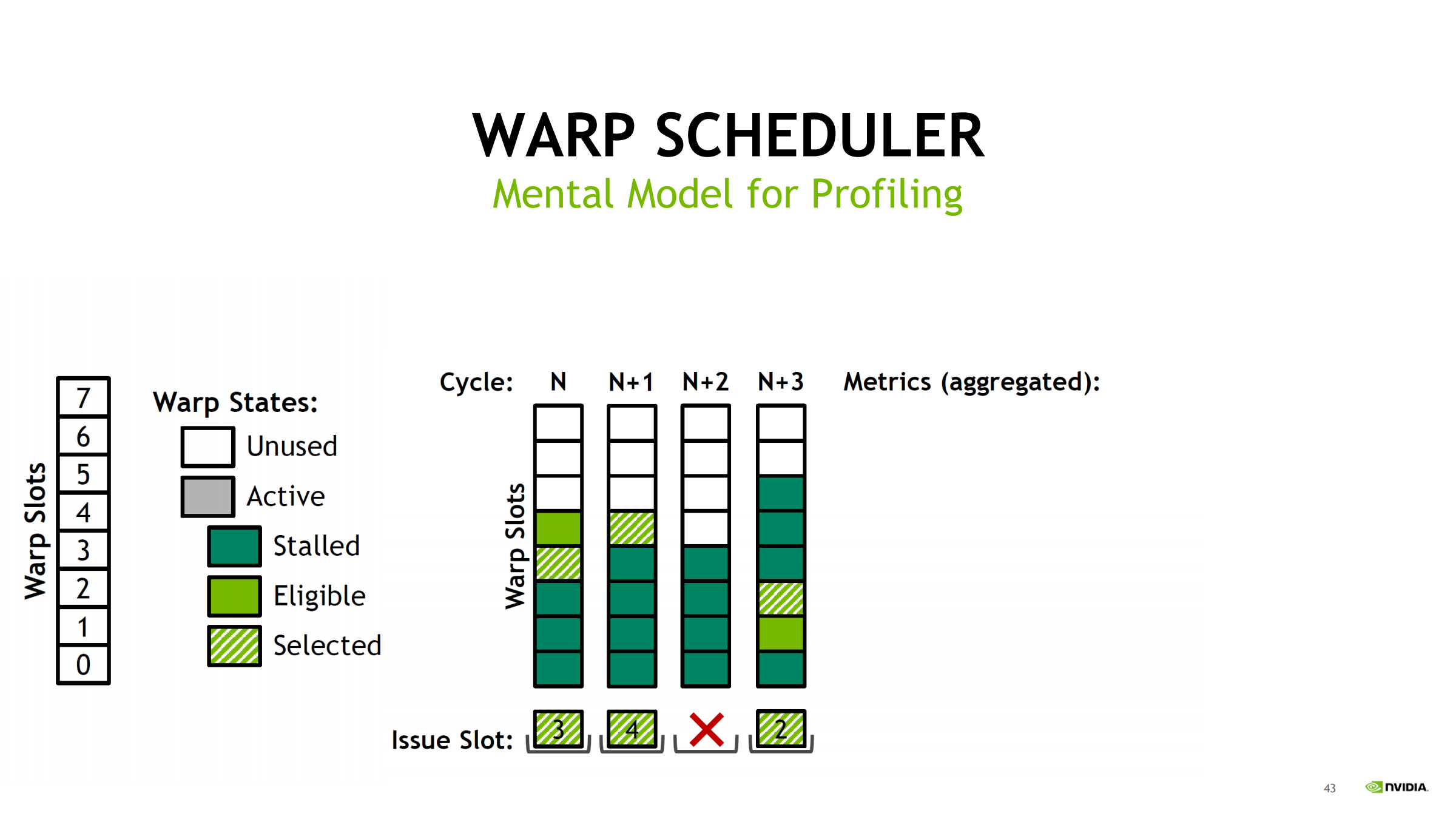
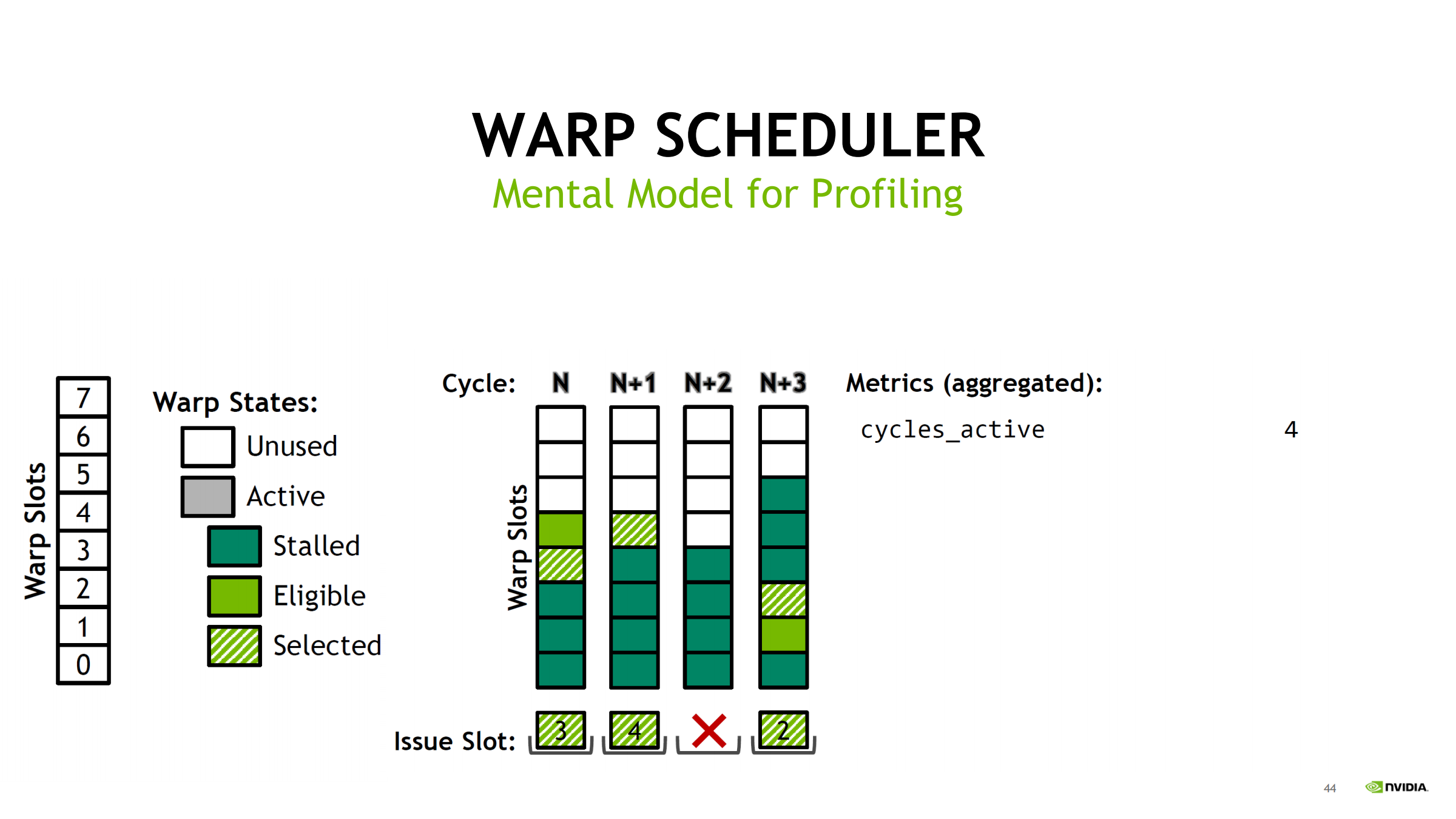
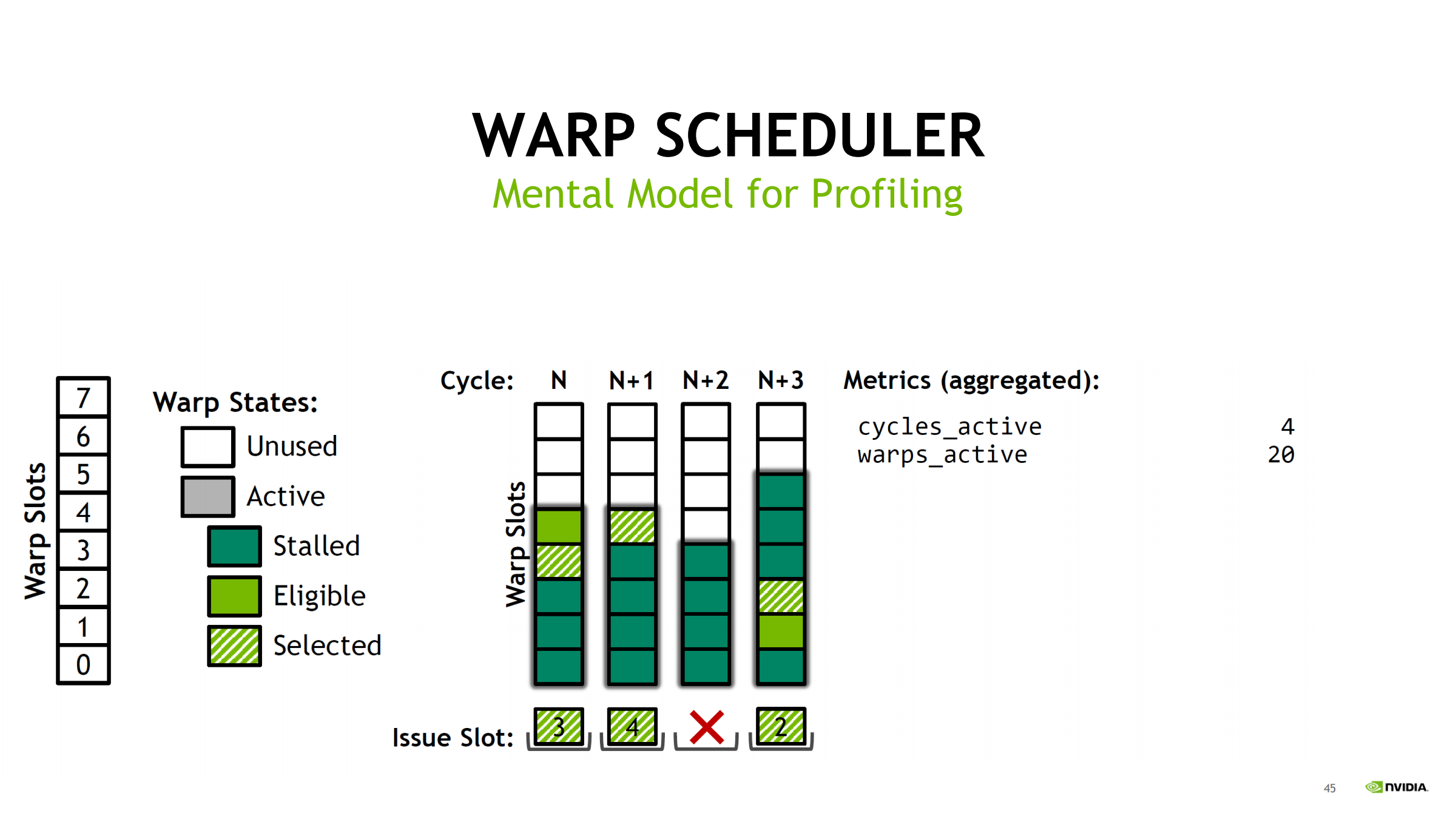
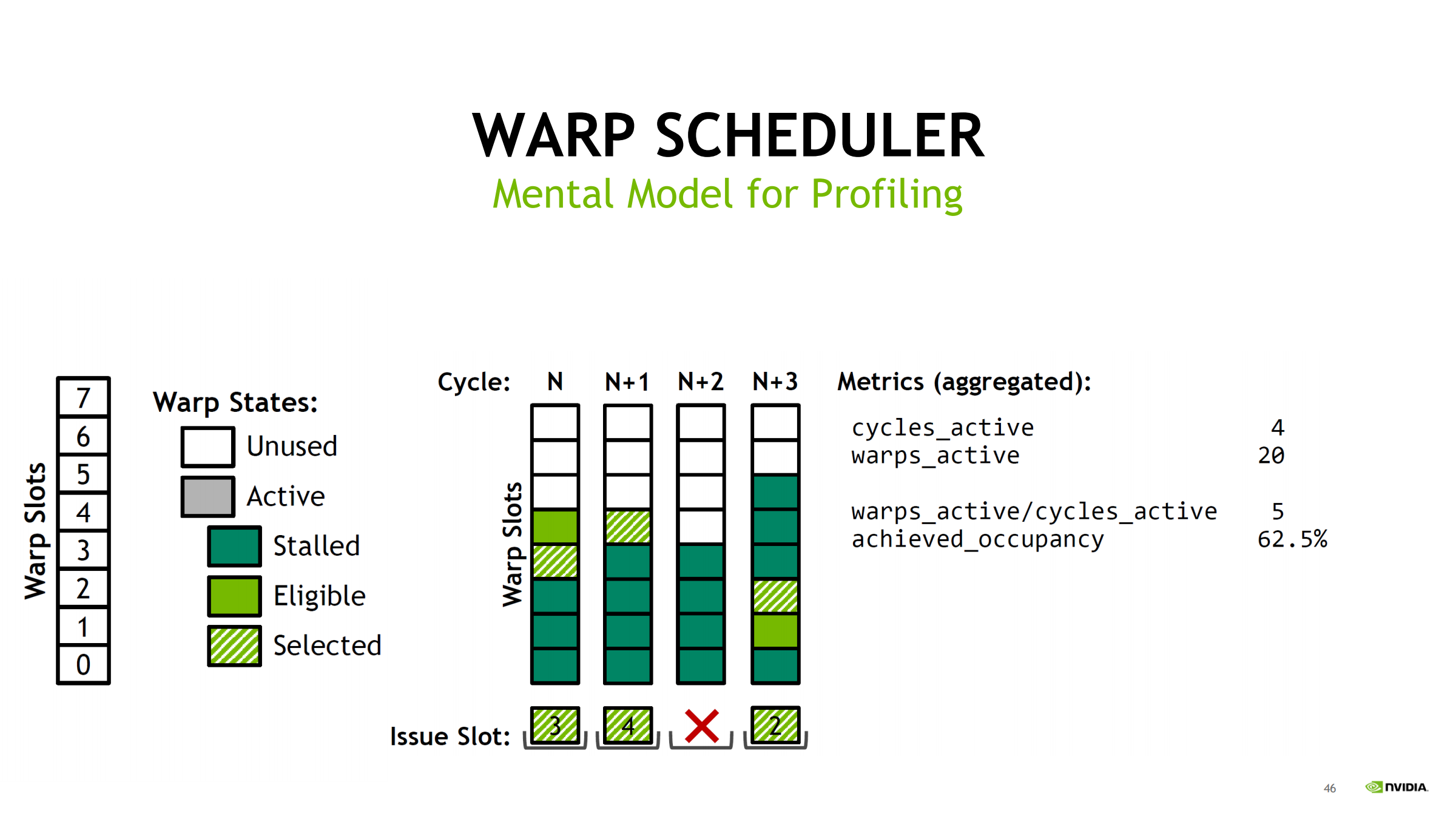
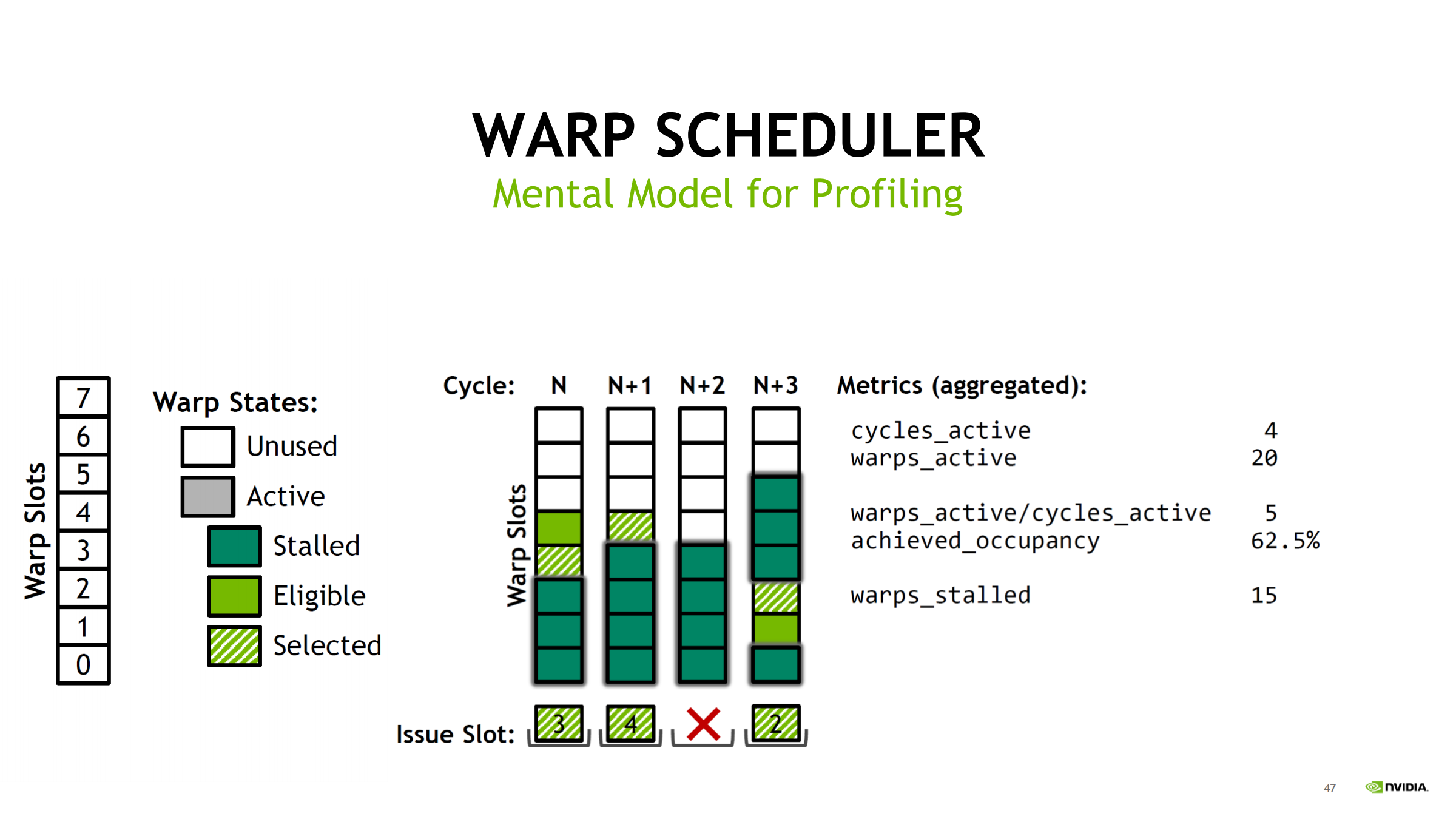
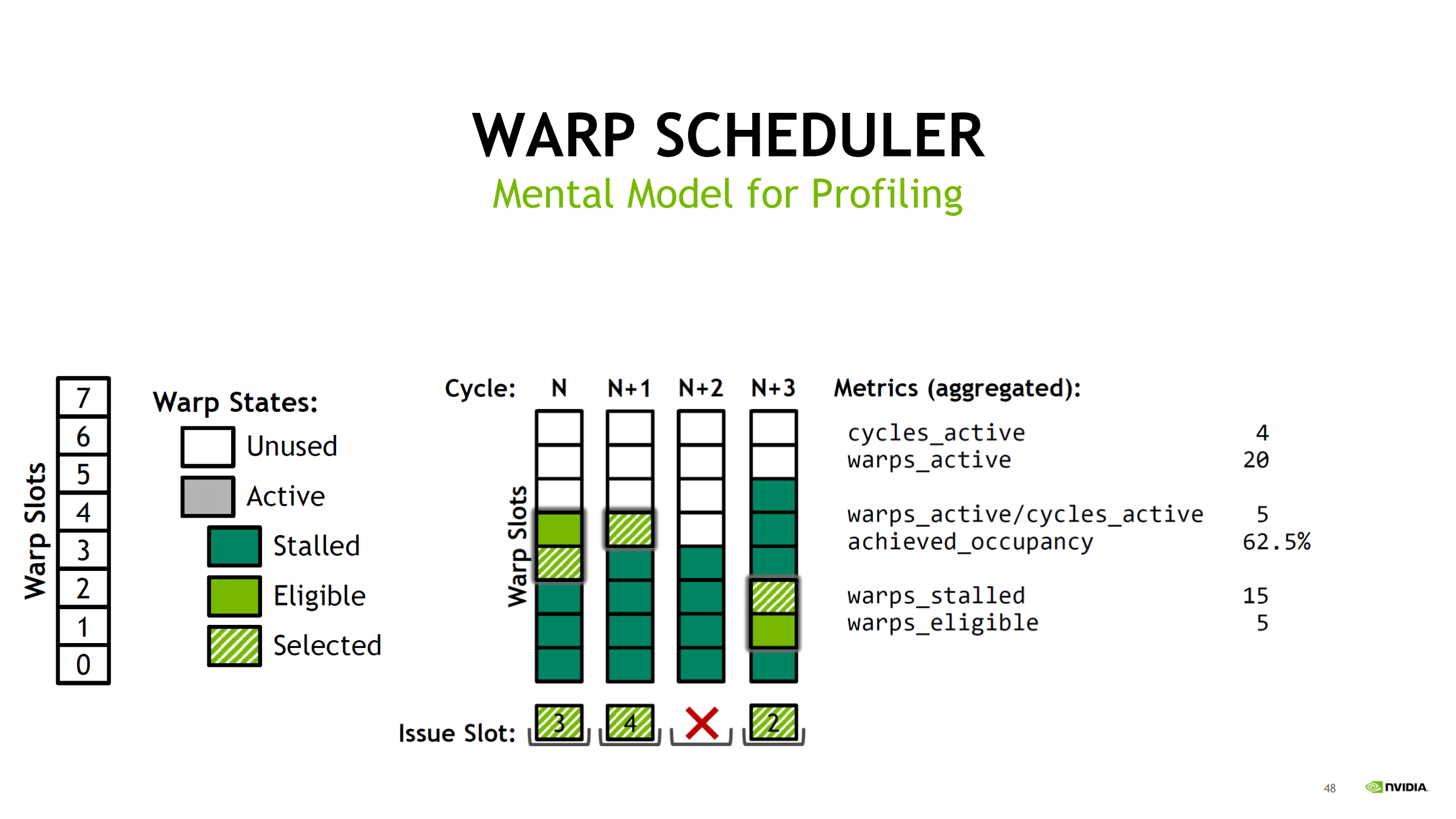
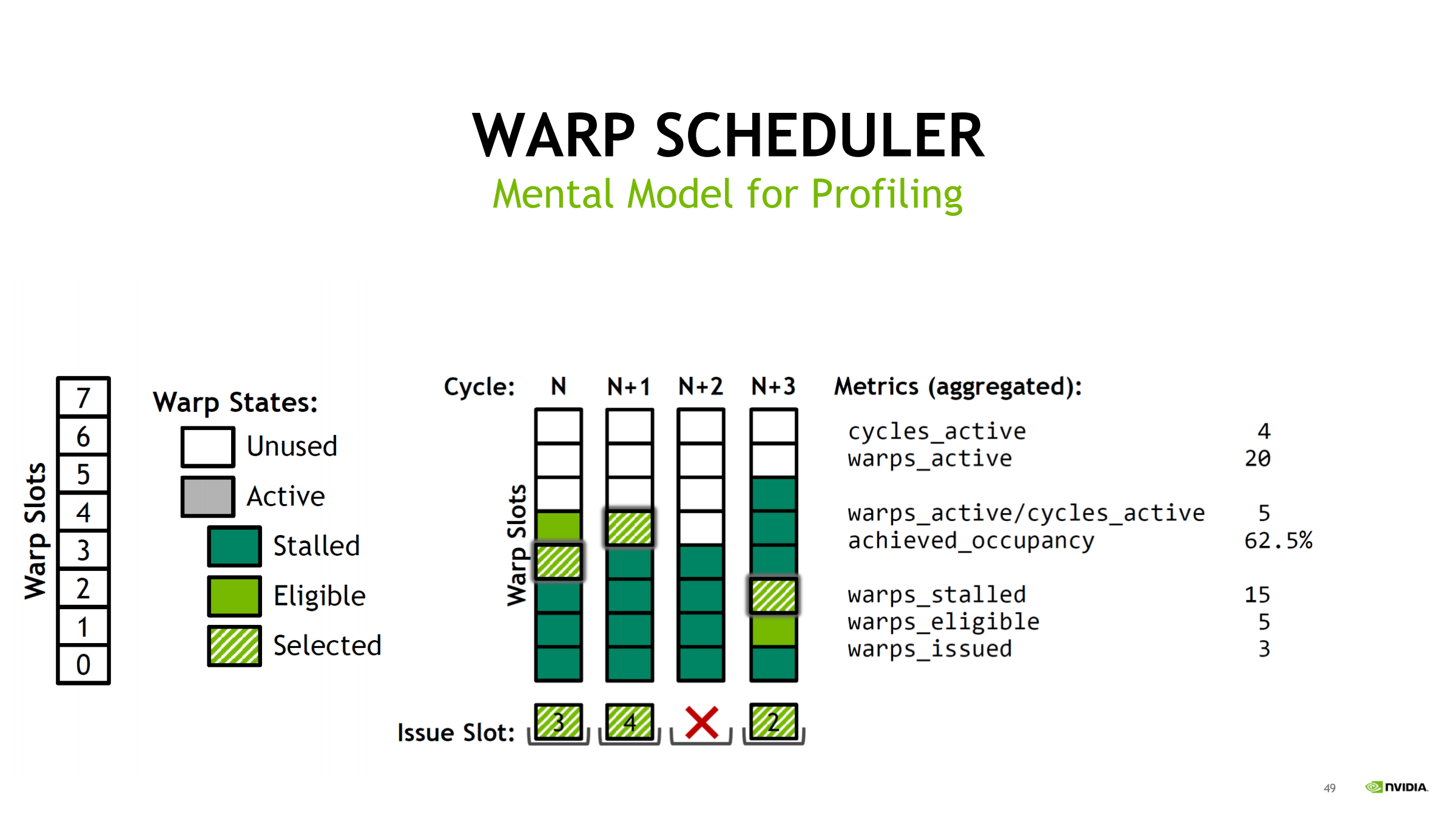
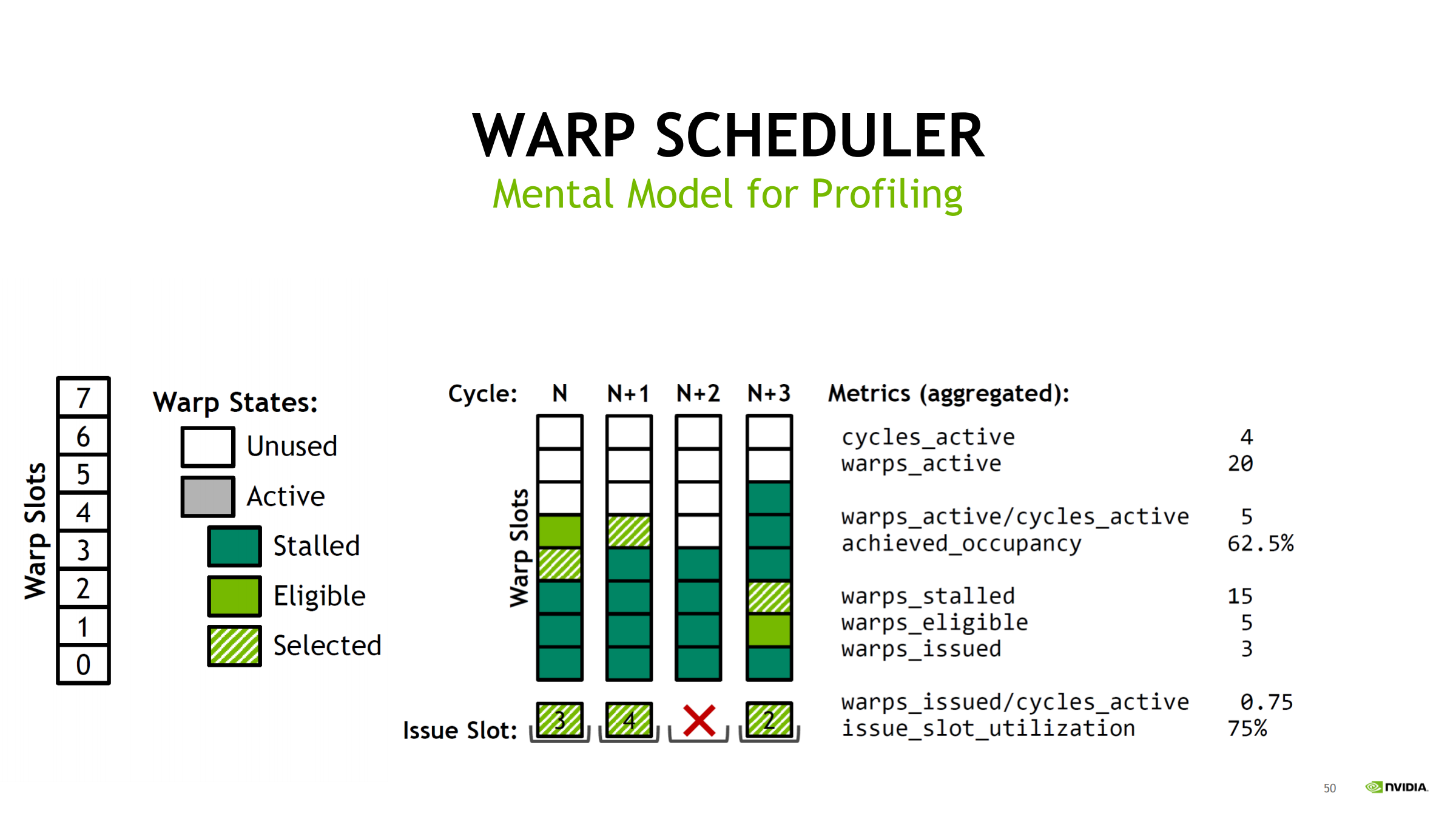
用 Turing(每 scheduler 8 slot)举例,统计 4 个 cycles:
- cycles_active = 4
- warps_active = 20 → 平均 active/cycle = 20/4 = 5
- achieved_occupancy = 5/8 = 62.5%(scheduler slot 视角)
- warps_stalled = 15
- warps_eligible = 5
- warps_issued = 3 → issued/cycle = 3/4 = 0.75
- issue_slot_utilization = 3/4 = 75%
诊断漏斗:
- occupancy 低 → 池子小、易无人可发
- stalled 多、eligible 少 → 延迟/等待型
- issued/utilization 低 → 结果:经常 no eligible
31. Memory Workload Analysis:拆内存瓶颈(Mem Busy / Max BW / Mem Pipes Busy)
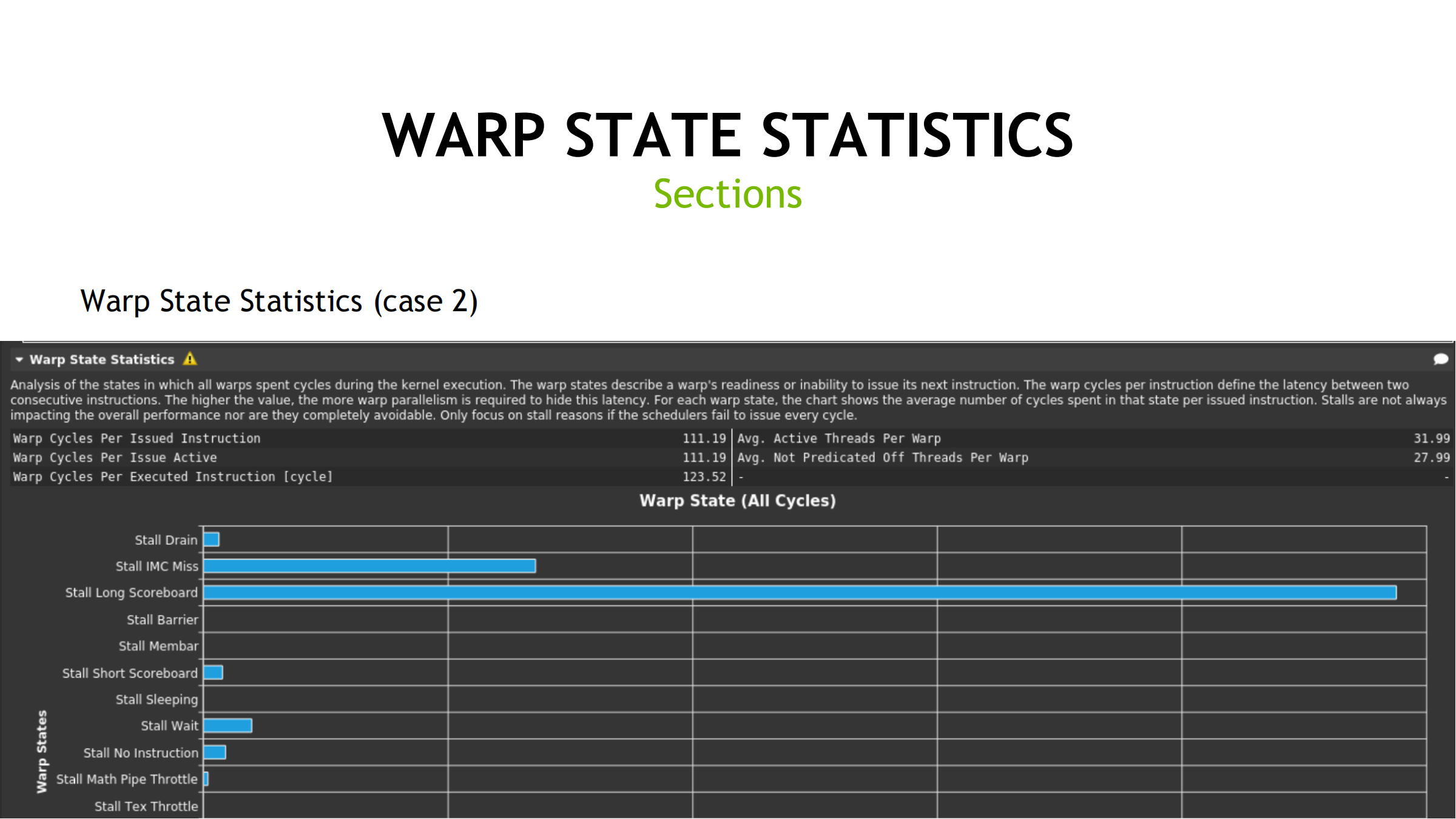
当 Warp State 显示 stalled_long_scoreboard 很高时,常见下一步:
- 切到 Memory Workload Analysis
- 目的:拆清楚是
- Mem Busy(单位忙/延迟等待)
- Max Bandwidth(带宽到顶)
- Mem Pipes Busy(内存指令发射吞吐到顶)

进一步定位:
- DRAM/L2/L1/TEX/Shared 哪层限制
- 读/写/原子/请求数过多等原因
常见优化方向:
- coalescing
- 减少请求数量
- shared 复用
- 减少 bank conflict
- 对齐/压缩访问
32. Memory Hierarchy 图:三类信息一起看
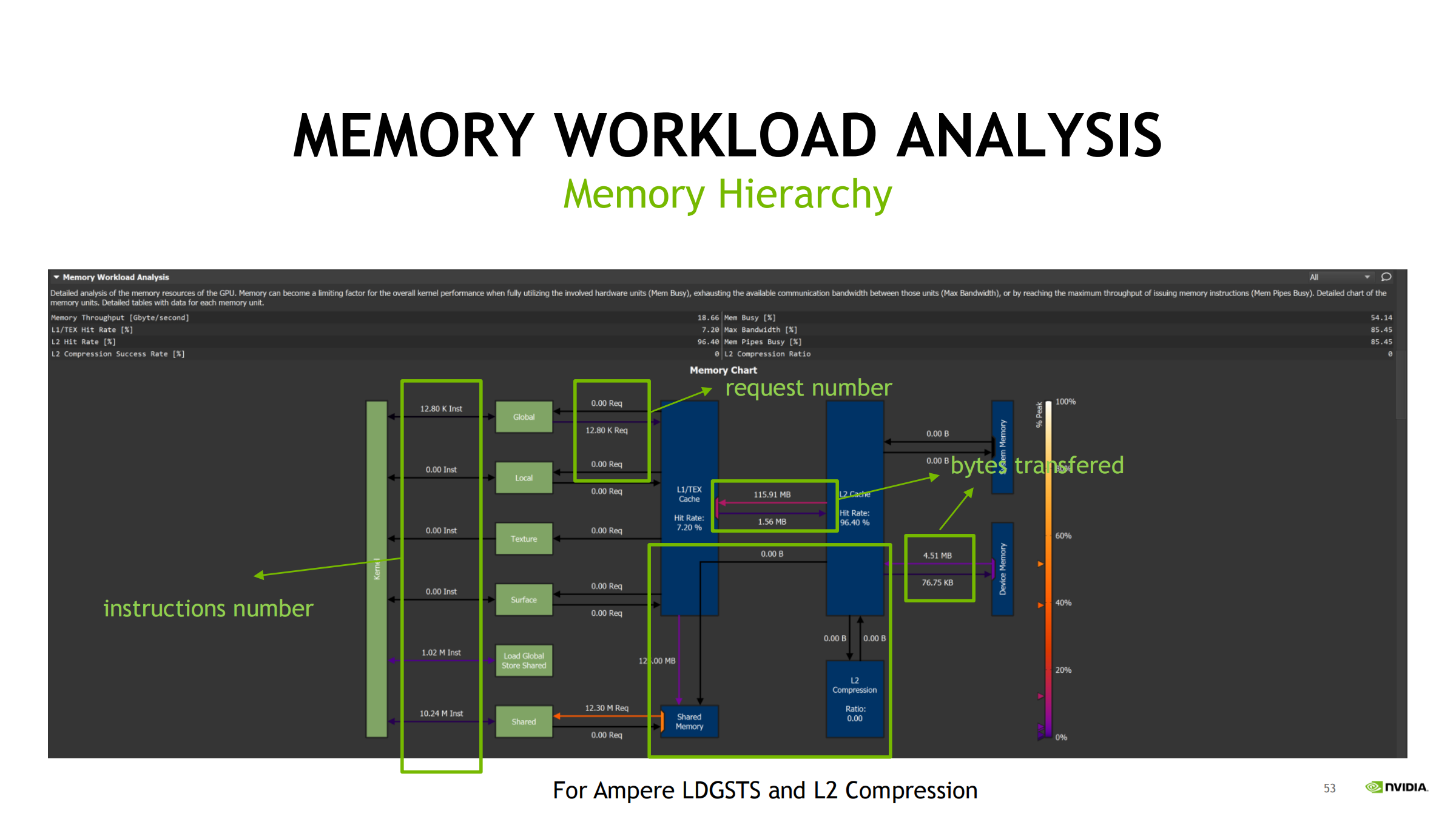
Memory hierarchy 图把三件事放在一起:
A) instructions number(按 warp 计)
B) request number(各层之间 request/sectors)
C) bytes transferred(真实传输字节)
诊断思想:
- instructions 多 + request 多 + bytes 大 → 本身访问重
- instructions 不多但 request 很多 → 不合并/冲突/原子导致放大
- bytes 远高于理论需要 → 多余传输/重复搬运
关键字段理解:
- sector:32B 粒度
- sectors per request:合并/访问模式效率信号
- hit rate:命中率(结合 request 与下层请求推断)
- shared:重点看 bank conflict(会放大传输次数)
Ampere 提示:
- LDGSTS 与 L2 compression 会影响 bytes transferred 观感
实操顺序:
- 先看 bytes transferred 最大的路径
- 看对应 request / sectors per request 是否放大
- 看 hit rate 判断 miss 是否高
33. Memory Report:按层看访问量/效率/吞吐

对每层(Shared / L1-TEX / L2 / DRAM)回答:
- 做了多少访问(instructions)
- 请求/事务(sectors/transactions)
- 命中率与效率(hit rate、sectors/request、bank conflict)
- 吞吐(throughput = bytes / time)
读表优先级:
- 先处理 shared 的 bank conflict(会污染一切、放大传输)
- 再看 global load/store 的“理论传输量 vs 实际传输量”
- 实际明显大于理论 → 不合并/对齐差/重复搬运/请求过多
34. Launch Statistics:资源占用如何限制 occupancy

用于理解 launch 配置与资源限制:
- registers per thread
- static/dynamic shared memory
- waves / waves per SM
- theoretical vs achieved occupancy
木桶原理:
- 寄存器限制 blocks/SM?
- shared memory 限制 blocks/SM?
- 线程/block 与硬件上限限制?
优化方向:
- 降寄存器压力(代码重构/减少临时变量/控制 unroll 等)
- 调整 block size
- shared 分块策略优化
occupancy 低 → eligible warps 少 → 更难隐藏延迟(常与 long scoreboard 呼应)。
35. Source Counters Statistics:把瓶颈落到“指令/源码行”

解决的问题:
- 哪条指令/哪行 CUDA 代码最耗、最卡、最不高效?
常见统计:
- Sampling Data(热点 PC/指令)
- Not Issued(发不出去的统计)
- Most instructions executed(执行次数最多)
特别价值:
- 直接提示 low efficiency memory:
- shared bank conflict
- global non-coalesced
- 可点击 PC 跳回源码定位可改点
36. Source Page:CUDA C/C++ ↔ PTX ↔ SASS 映射
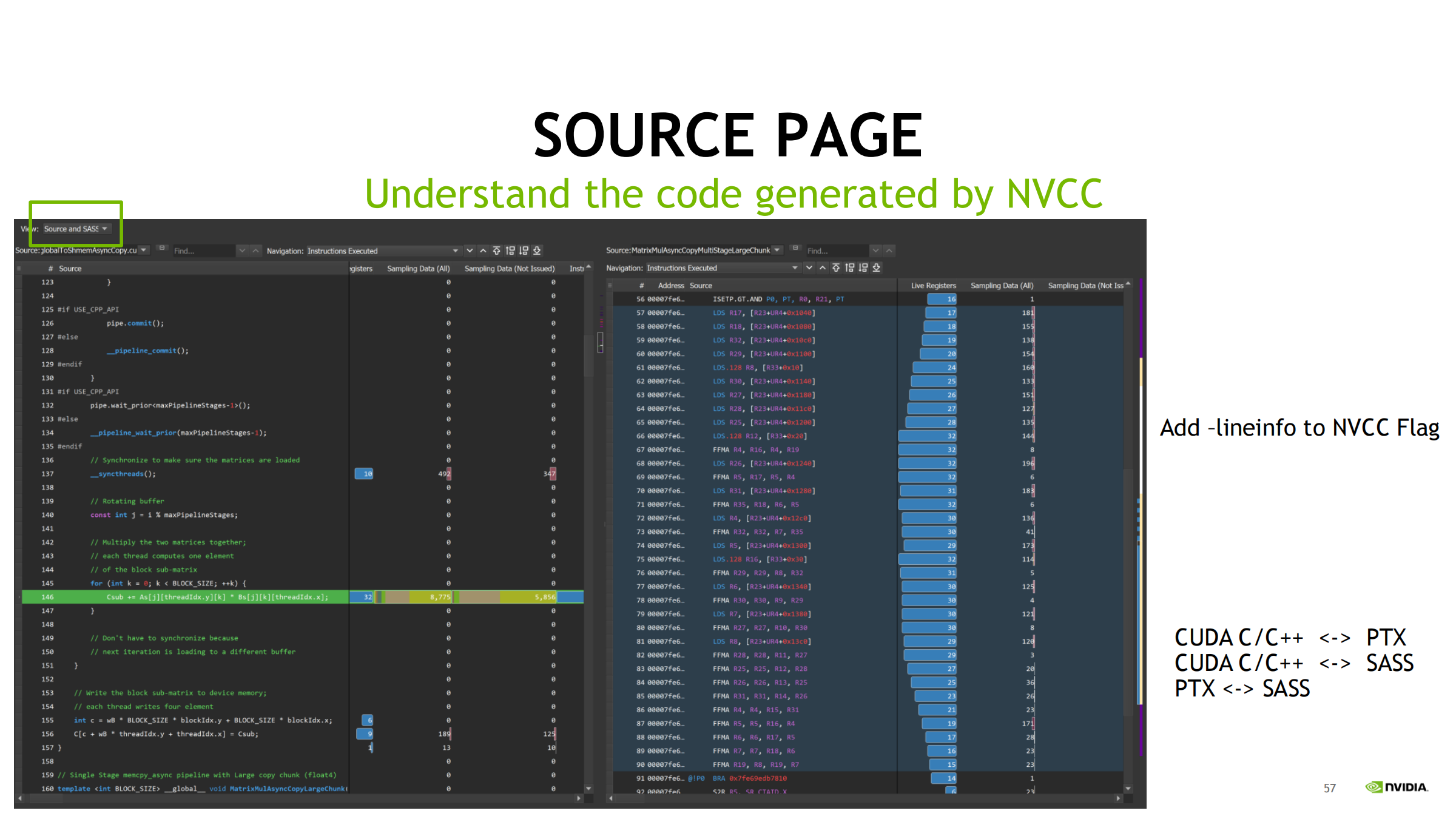
用途:
- 理解编译器生成了什么指令
- 哪条 SASS 指令在 stall、对应哪个源码行
三种映射:
- CUDA C/C++ ↔ SASS
- CUDA C/C++ ↔ PTX
- PTX ↔ SASS
关键前提:
- 编译加 -lineinfo 才能更准确映射
- 建议流程:先高层指标定位 → 再用 source/sass 证实与精修
不建议一开始就盯 SASS
37. Stall reason 速查:含义 → 常见触发条件


- Long Scoreboard:等 global/local/surface/tex 结果回来(长延迟依赖)
- Short Scoreboard:shared 结果依赖、频繁 MUFU 或动态分支等(短延迟等待)
- LG Throttle:local/global 访存队列太满(访存指令太多太密)
- MIO Throttle:MIO 队列太满(大量 LDS/MUFU/动态分支)
- Math Pipe Throttle:计算管线忙(吞吐受限)
实践:不要只看名字,要结合访问模式、bank conflict、分支、MUFU、指令混合判断。
38. Long Scoreboard:等内存结果(指针追逐例)
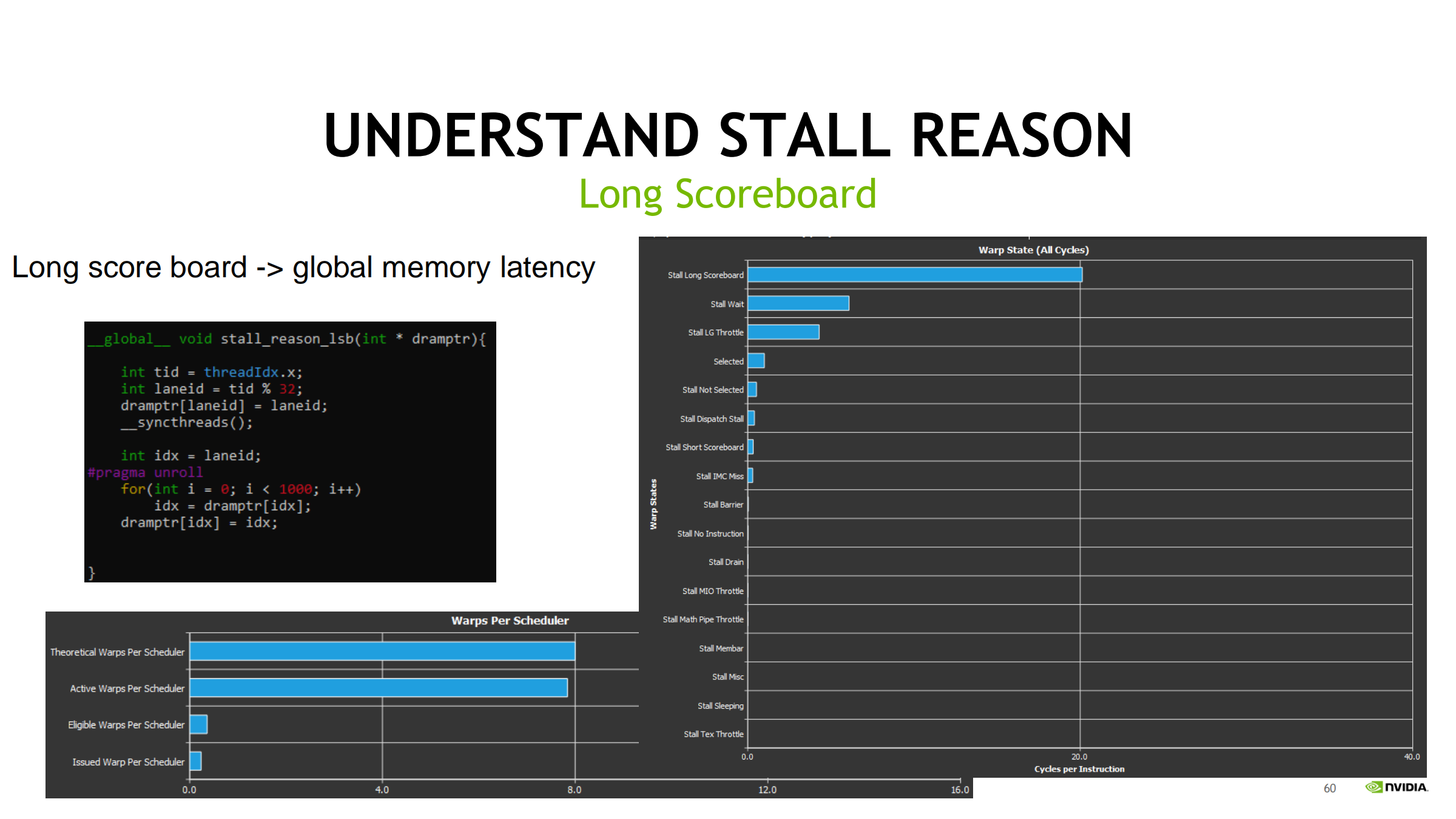
- 本质:load 数据没到 → 依赖指令无法发射
- 指针追逐(load 结果立刻用于下一次 load 地址)会形成强依赖链:
- ILP 很低
- 只能一直等 DRAM 往返
- Long Scoreboard 爆表
优化思路:
- 更多并行度隐藏延迟(更多 warps/occupancy)
- 提高缓存命中与合并访问
- 打断 pointer chasing 依赖链(数据结构/访问顺序/批量化分块)
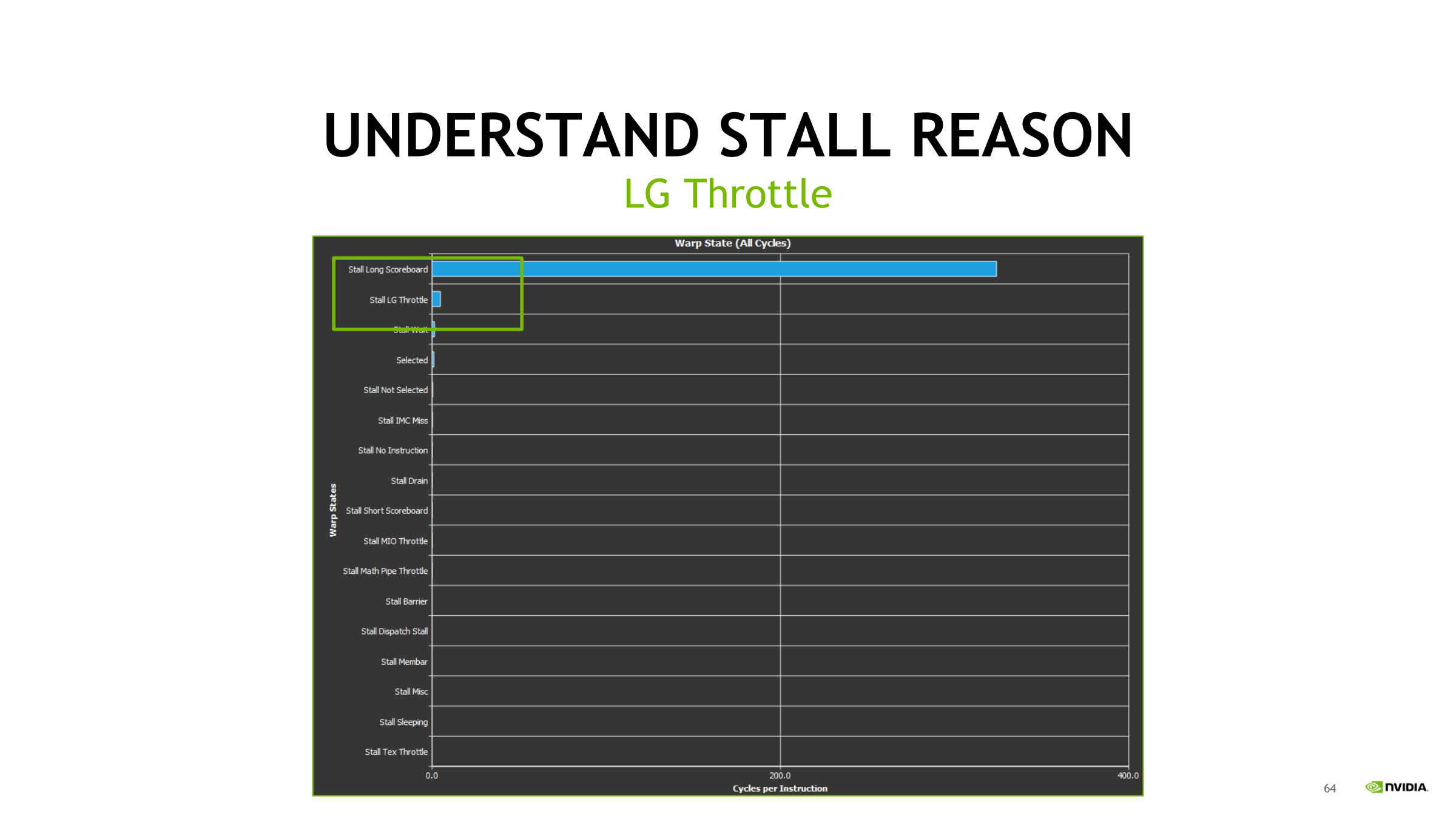
39. LG Throttle:等队列/入口(请求太密)

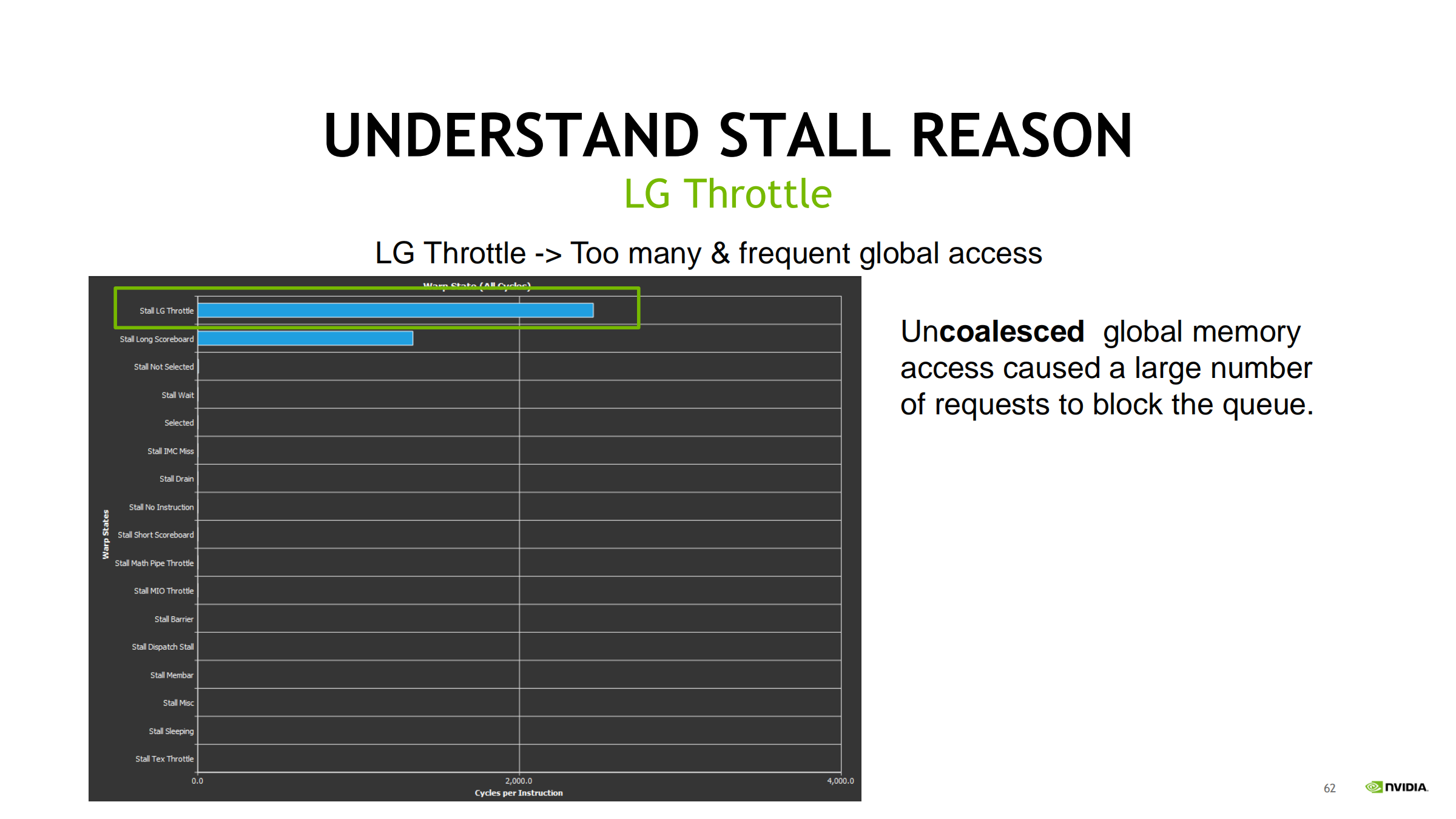
区别于 Long Scoreboard:
- Long Scoreboard:等“数据结果”(latency)
- LG Throttle:等“队列空位”(throughput / 请求密度)
常见触发:
- 循环里 ld/st 指令密度过高
- uncoalesced 访问导致 request 爆炸
- local memory 访问频繁(常来自寄存器 spill)
交叉验证证据链:
- Instruction mix:ld/st 是否异常高?有无大量 ld.local/st.local?
- 内存请求/吞吐是否接近瓶颈
优化方向:
- 减少 global/local 指令数量与频率(缓存到寄存器/shared、算子/循环融合)
- 改成 coalesced(连续/对齐)
- 向量化(每条指令搬更多字节)
- 降 spill(降寄存器压力/减少 unroll)
40. uncoalesced → coalesced:LG Throttle 的经典对比

- uncoalesced:warp 内地址分散 → 拆成大量 request → queue 被堵 → LG Throttle 飙升
- coalesced:warp 内访问连续/对齐 → request 大幅减少 → LG Throttle 显著下降
“总字节量固定”下:向量化减少访存指令条数
即使都是 coalesced,只要访存指令太多太密,也会 LG Throttle。
思路:
- 总访问字节量固定
- 让每条 ld/st 搬更多字节(1B → 4B → 8B → 16B)
- 指令条数下降 → request 压力下降 → 时间变短
示例(同样总量):
- 1B:834 µs
- 4B:220 µs
- 8B:143.14 µs
- 16B:122.91 µs
注意前提:
- 对齐(如 16B 访问最好 16B 对齐)
- 别引入寄存器压力暴涨导致 spill
41. SOL 对比多版本 LG kernel:Memory 高、SM 低 → memory-bound

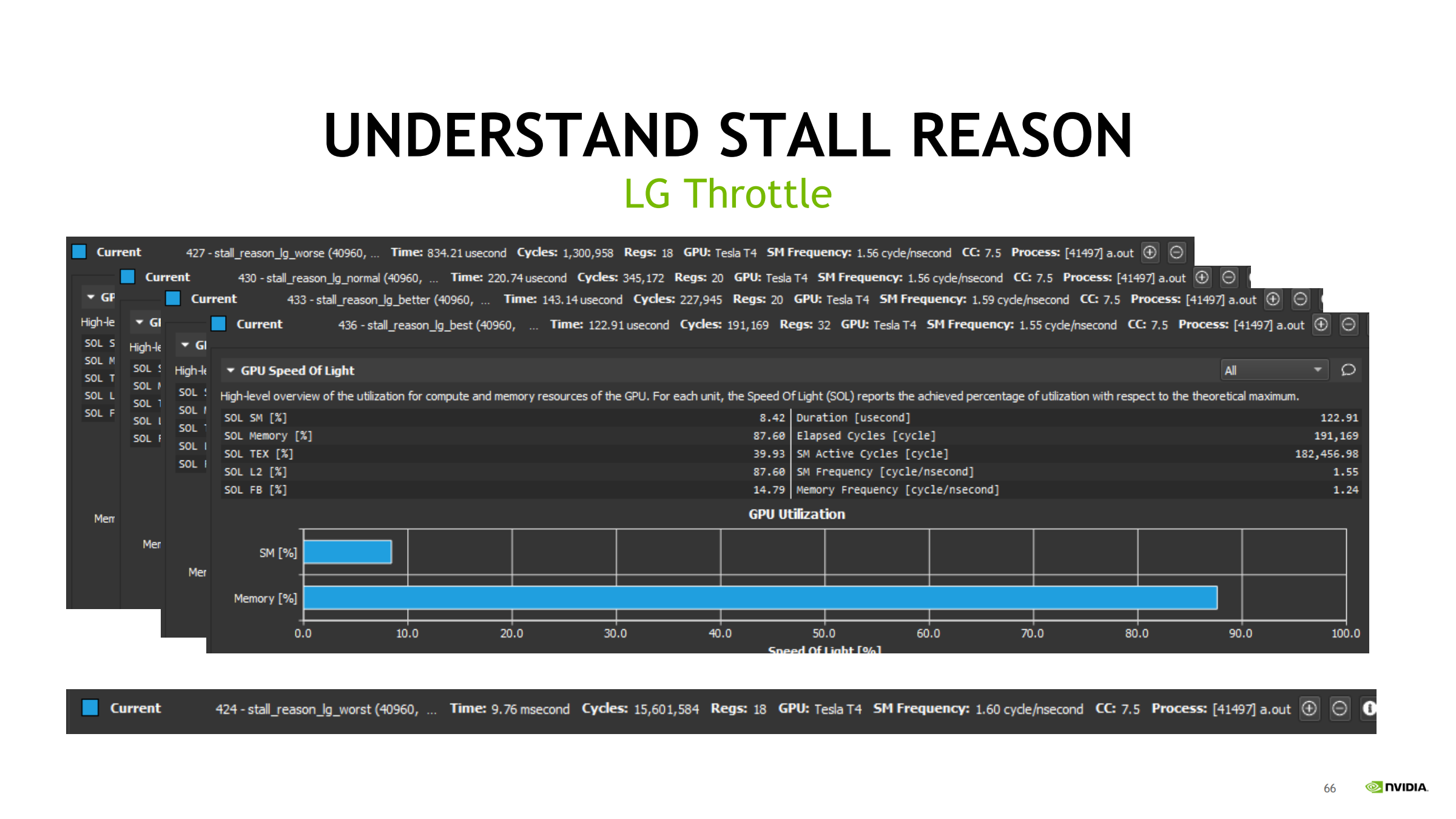
通过 SOL 可一眼判断:
- Memory ~80–90%
- SM ~10%
→ kernel 主要受限于 memory 通路/带宽,不是算力。
下一步方向:
- 继续减少总读写字节数
- 提高复用与命中(tiling/shared)
- 保持合并 + 向量化 + 对齐
42. Short Scoreboard:shared 依赖链 / MUFU / 动态分支

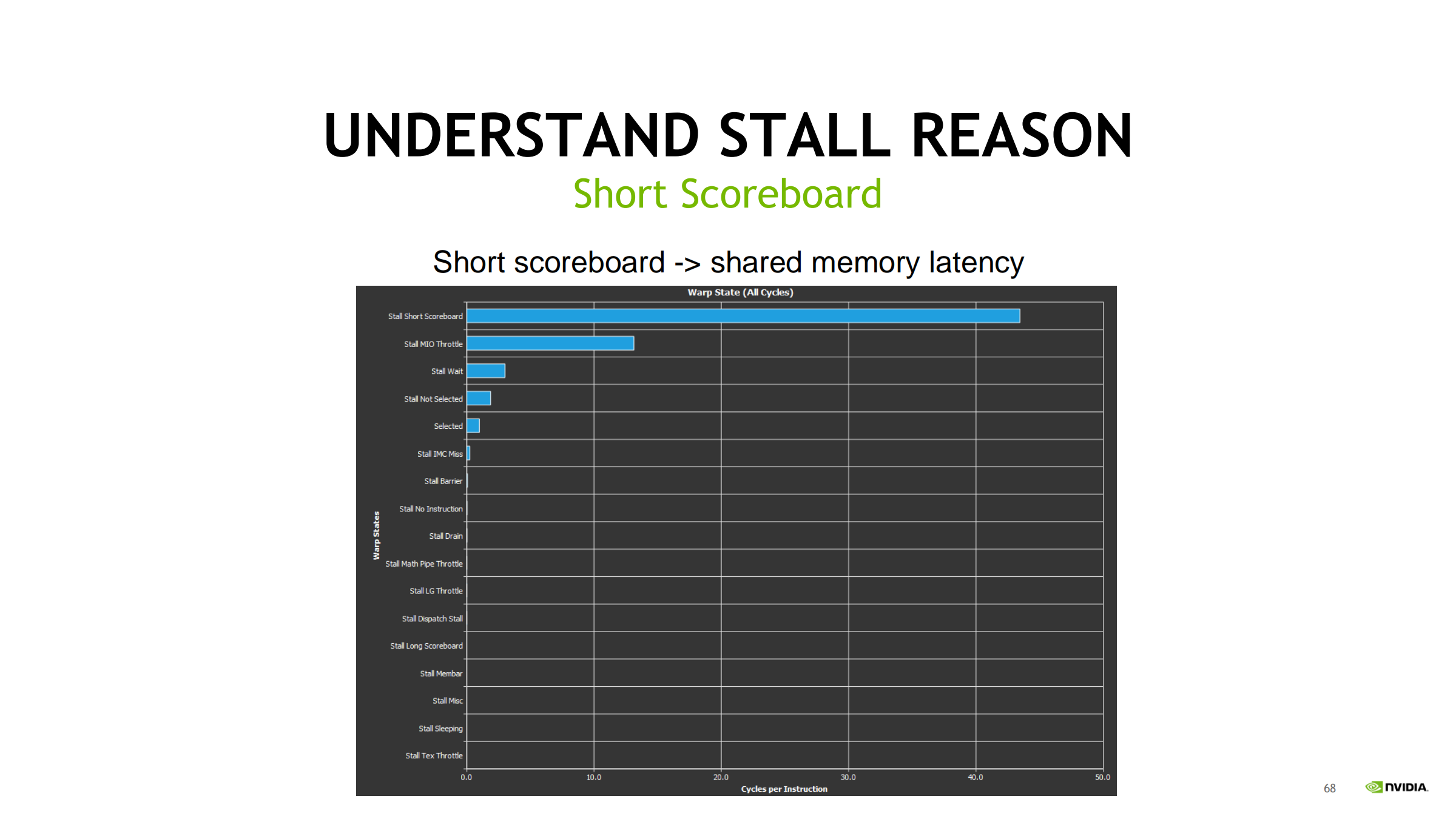
要点:
- 不等同于“shared 很慢”,更本质是“结果被马上用,依赖链太紧”
- 即使没有 bank conflict,shared load 结果立刻用也会产生 Short Scoreboard
若来自 shared:
- 优先排查 bank conflict
若来自分支:
- 减少分歧/改 predication
若来自 MUFU:
- 近似/查表/替换
43. MIO Throttle:MIO 管线/队列极度繁忙(bank conflict 放大 32×)



- 触发:大量 LDS(shared load/store)、MUFU、动态分支
- bank conflict 会把一次 shared 访问:
- 无冲突:Requests = 1 × instructions
- 完全冲突:Requests = 32 × instructions
(一次指令被序列化为 32 次 request,等价 31 次 conflict)
因此:
- bank conflict 会让 Short Scoreboard 更明显
- 同时把 MIO 压力放大,触发/放大 MIO Throttle
优化:
- 消除 bank conflict(padding/交错布局/改变索引)
- 减少 shared 访问次数(寄存器缓存、减少 round-trip)
- 降 MUFU/动态分支密度
44. Case Study 1:Transformer Encoder(nsys 定位 launch bound)

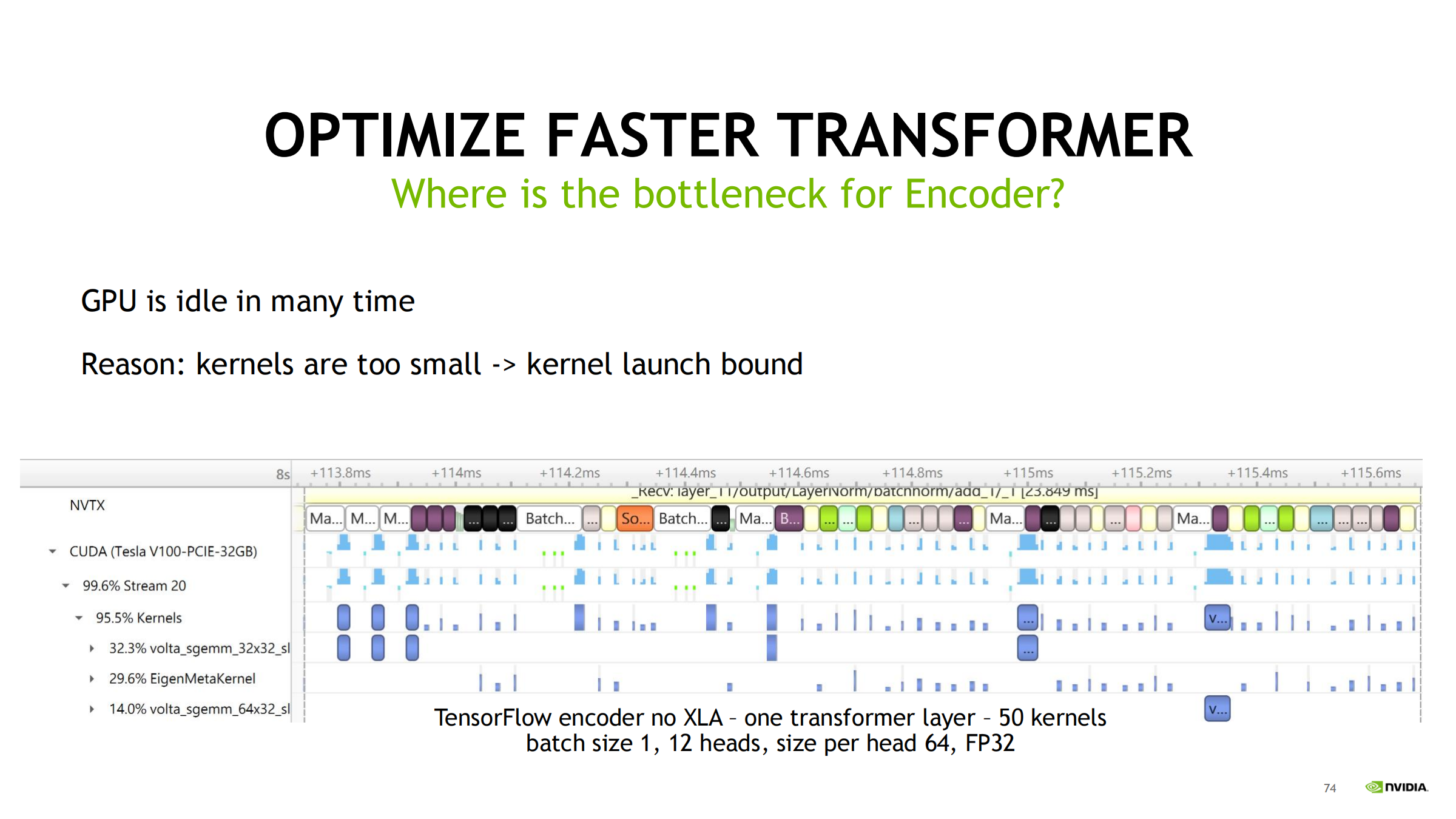
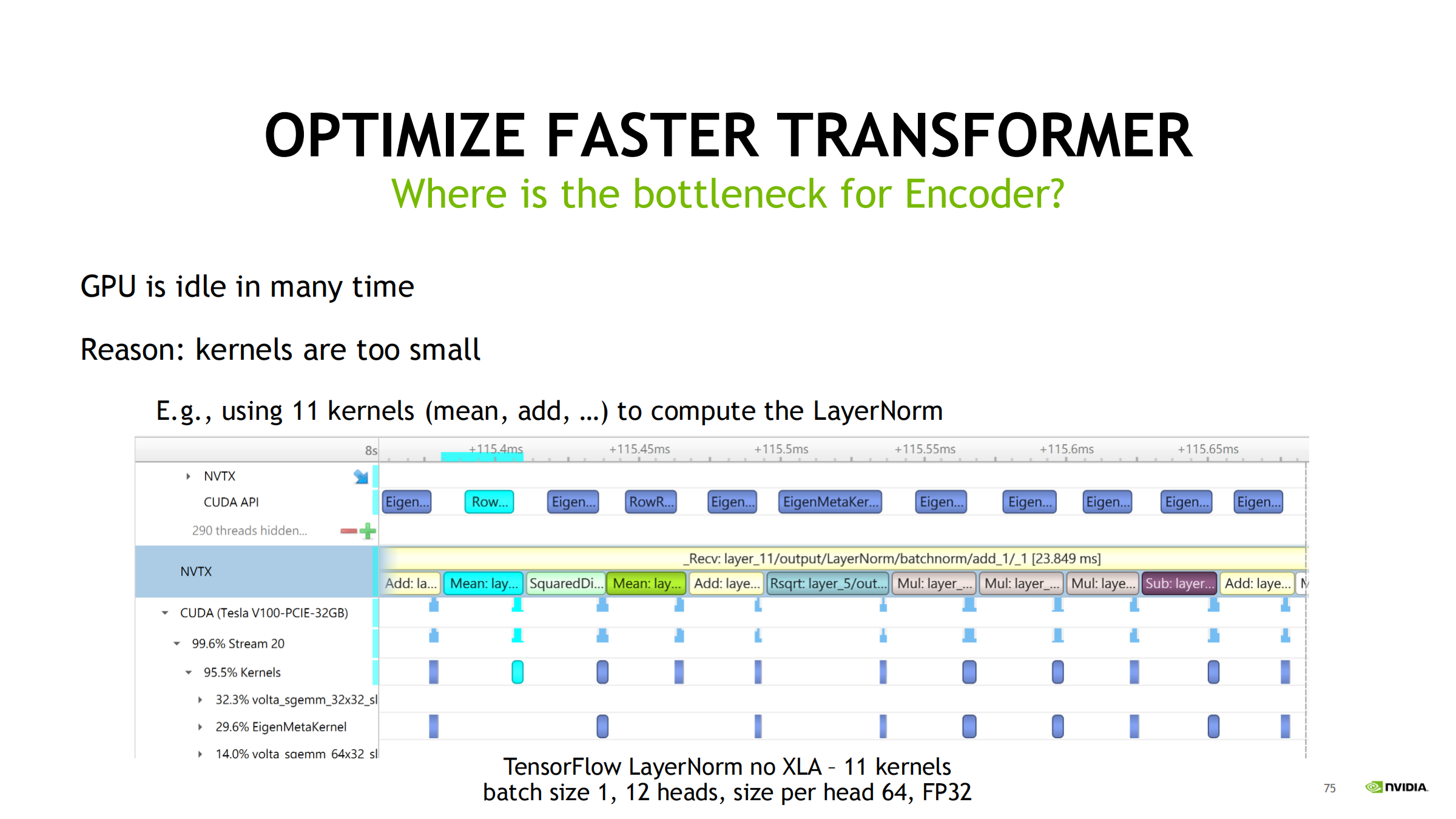

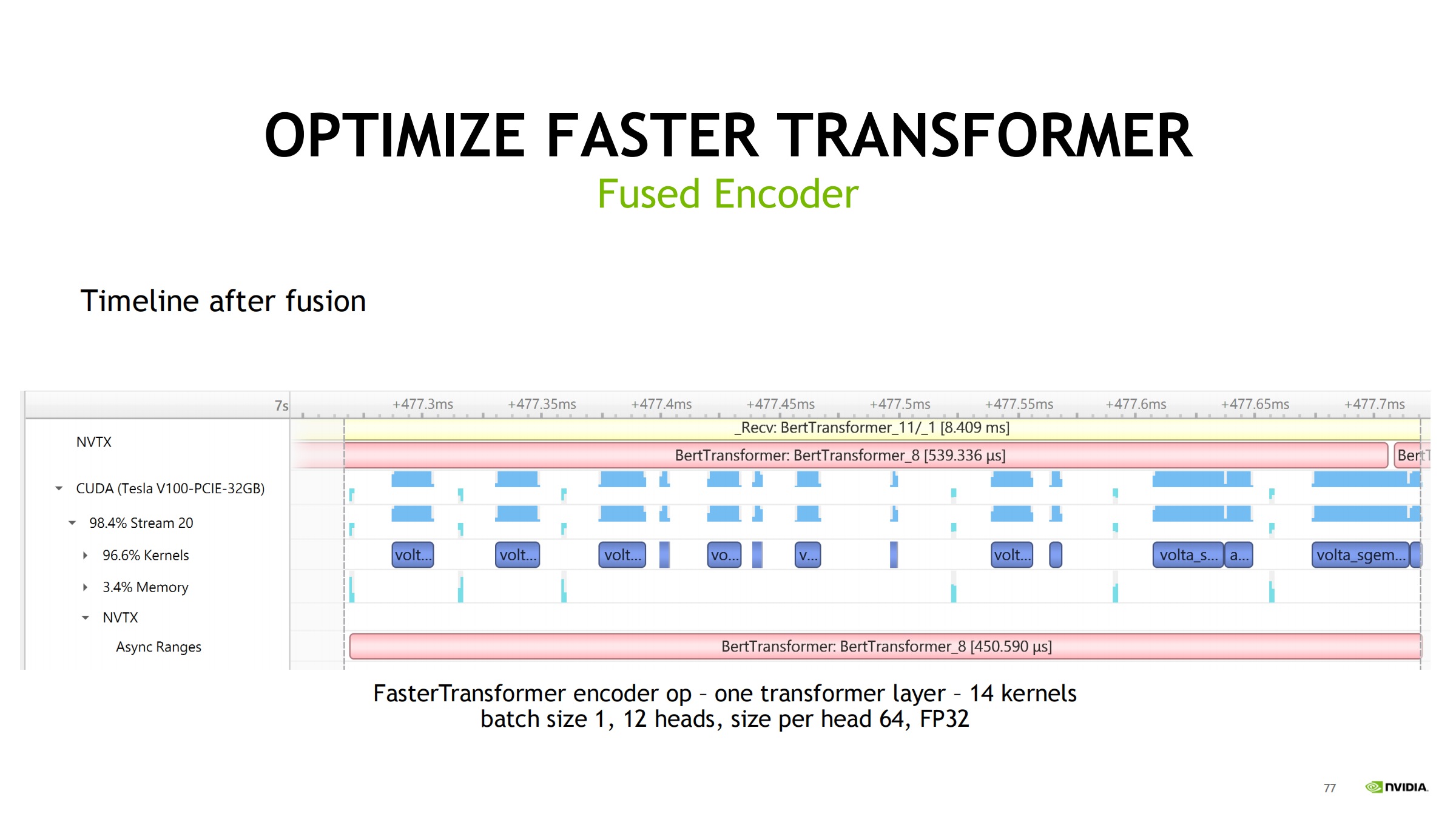
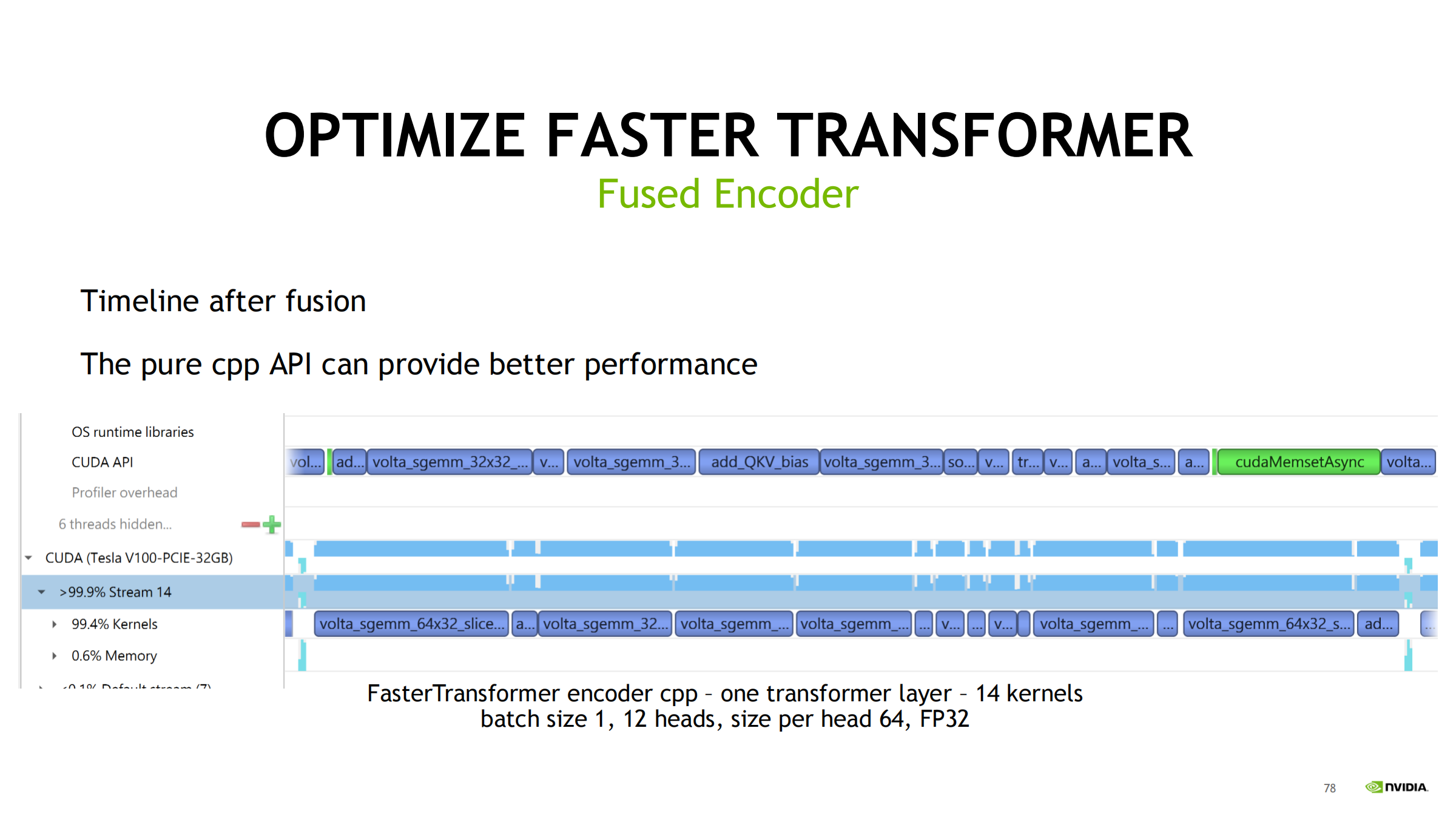
用 nsys 时间线看什么
- 先看 GPU 是否有大量 idle/gap
- 再对齐 CPU 线程/同步
- 再看 kernel 粒度与数量
现象:batch 小 + kernel 碎 → GPU idle(launch bound)
- TensorFlow 无 XLA:一个 layer 可能拆成几十个 kernel
- LayerNorm 甚至拆成多步(如 11 kernels)
- launch 开销 + 同步依赖造成大量空洞
优化路线(按效果递进)
- TF encoder 无 XLA:1 layer ~50 kernels,GPU idle 很多
- 开 XLA:50 → 24 kernels,好一些但仍有 idle
- FasterTransformer fused encoder:24 → 14 kernels,gap 明显减少
- 纯 C++ API:进一步减少框架开销,gap 近乎消失
结论:先用 nsys 看 timeline:大量 kernel gap → 先判为 launch bound/碎 kernel
优先手段:fusion(XLA / fused kernel / library) + 降 framework overhead(更低层 API)
45. Case Study 2:矩阵转置(ncu 解释 transaction 放大并优化)



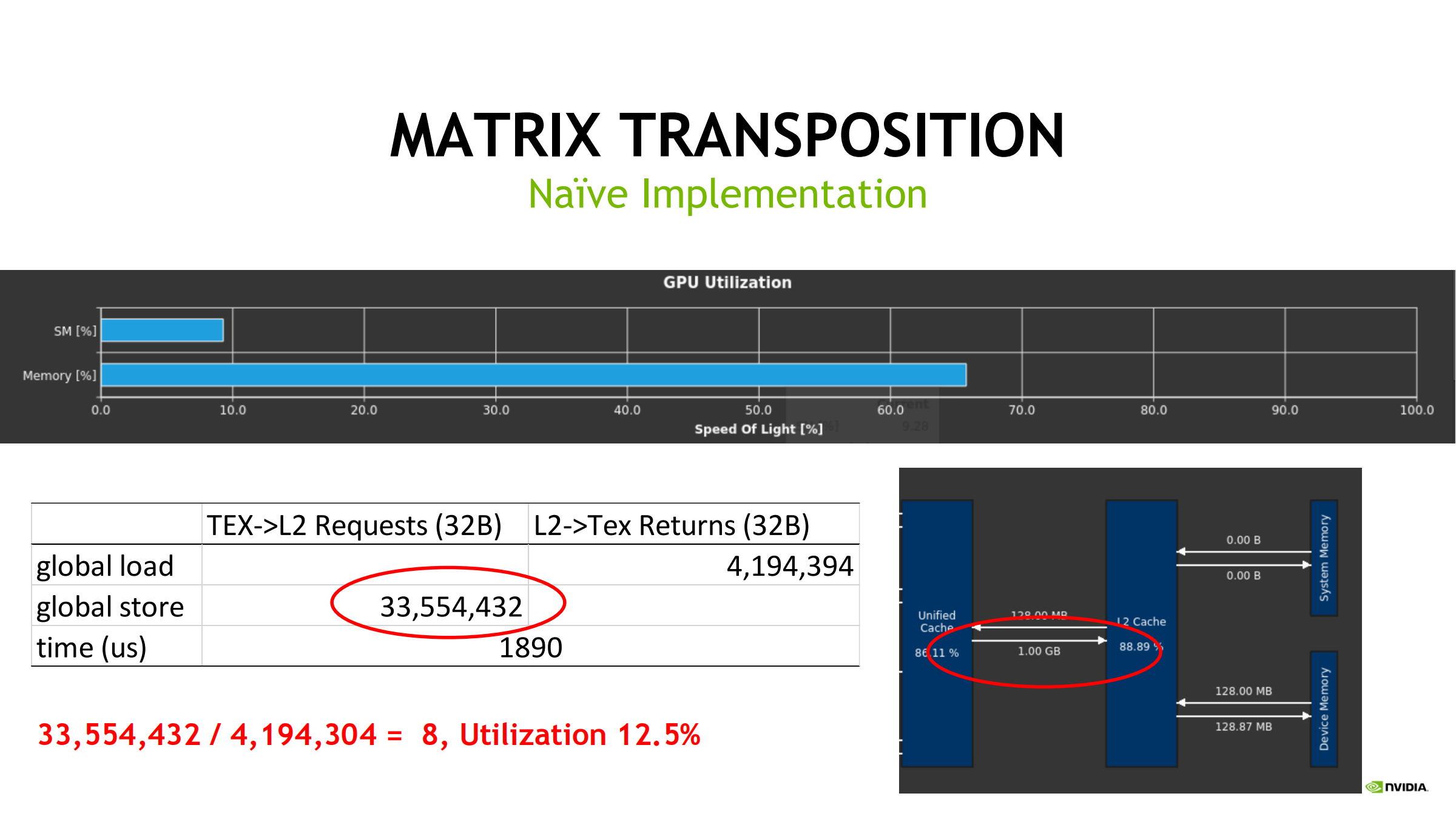
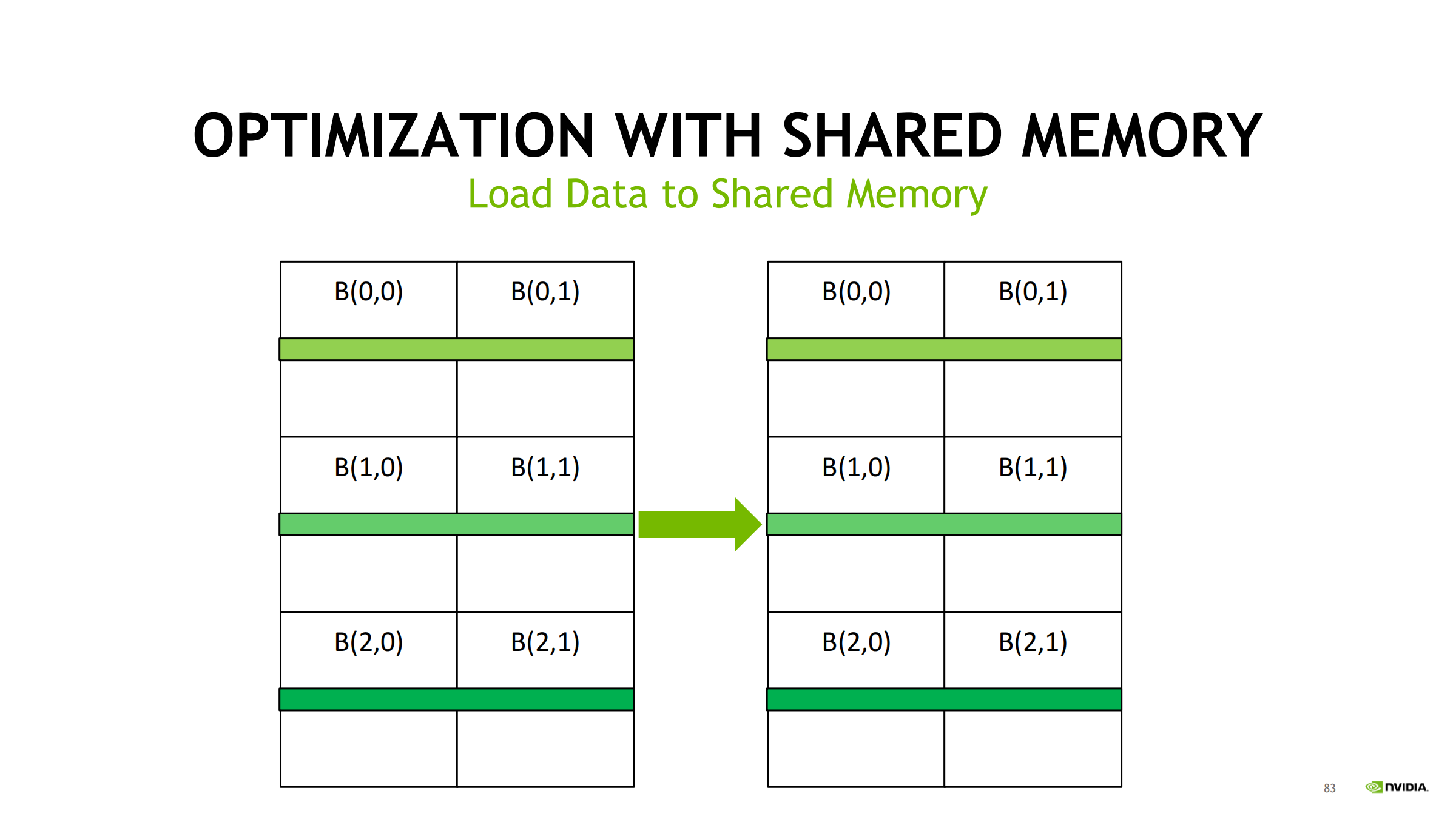

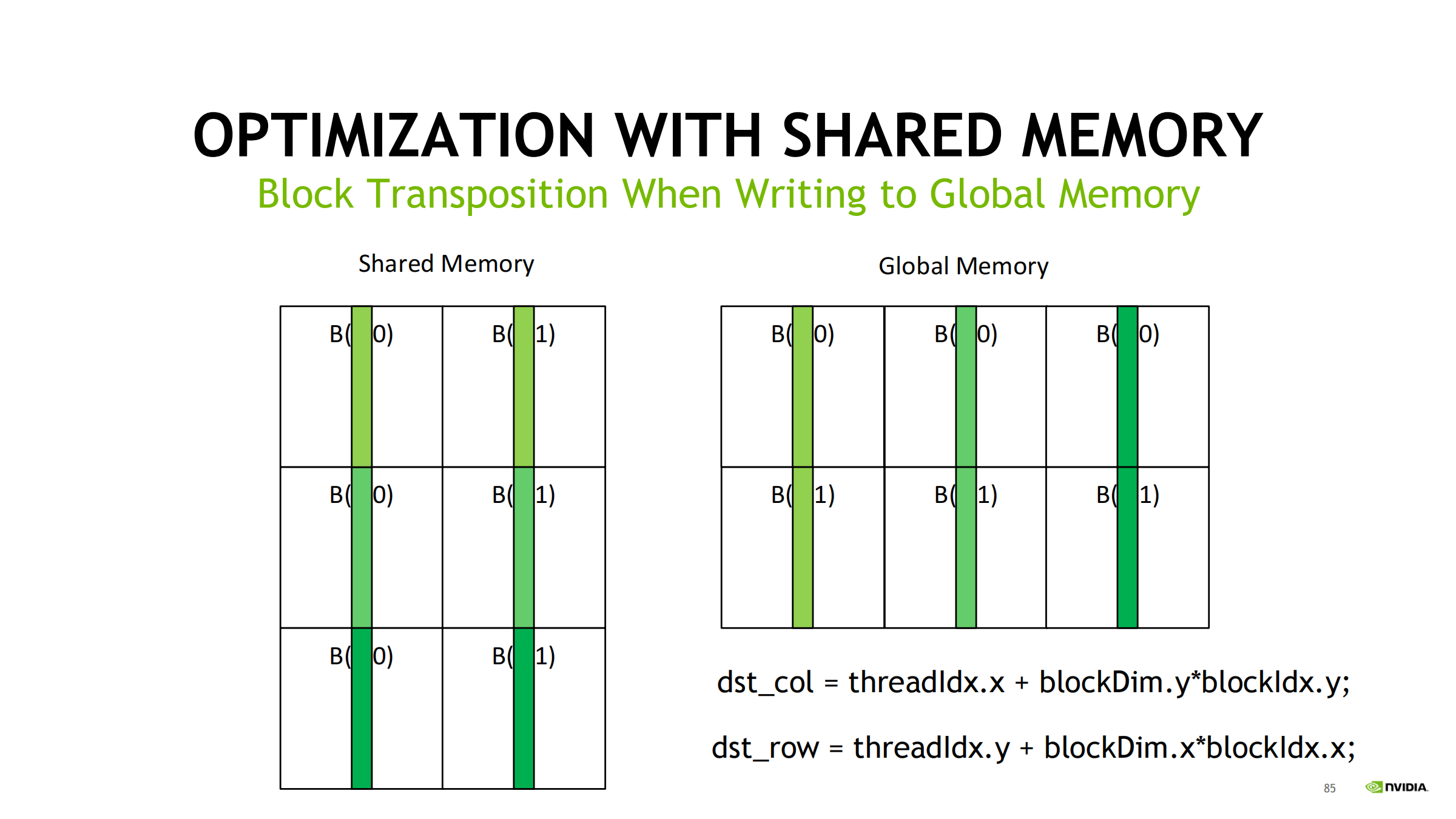

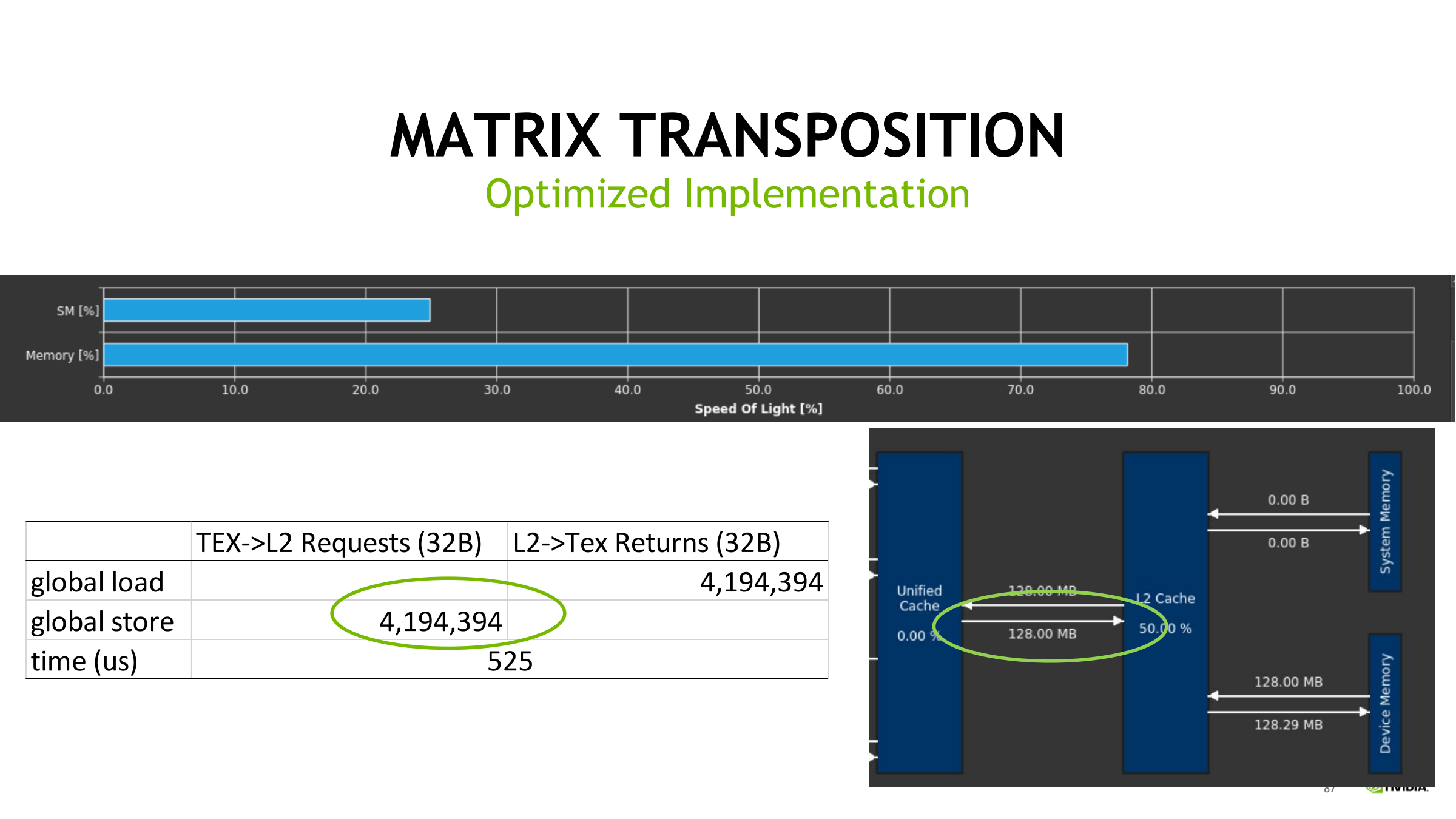
先算理论读写量与 transaction 参照线
- 转置难点:
- 读通常可合并
- 写常变成 stride 写(不合并)→ store transaction 放大
朴素实现(naive)
- 每线程读 input 一个元素并写到 output 的转置位置
- 写常不合并 → store requests 飙升(典型现象:理论量固定但实际 transaction 数巨大)
- 因此带宽利用率低
优化:shared tile 做“块内转置”
- 全局合并读 → 写入 shared
- __syncthreads()
- 从 shared 按转置顺序读 → 全局合并写
- sdata[32][33] 的 33 是典型 padding,用来避免 shared bank conflict
优化效果(典型)
- global store requests 大幅下降
- 耗时从 1890us → 525us
- 说明瓶颈确实在非合并写/请求放大
- 通过减少 transaction 数提升有效带宽利用率
46. Summary(总结合并)

- Nsight Systems:系统级 profiler(时间线,找同步/等待/搬运/空洞)
- Nsight Compute:kernel profiler(SOL、memory/compute/scheduler、stall reasons)
- profiling 需要 CUDA 与 GPU 架构基础
- 建议使用 nsys + ncu 替代 NVVP + nvprof
- Top-down 思路:
- 先整体定位机会点
- 再逐步深入
- 不要一上来就看 SASS
